
Yuriy Brun
Professor
Manning College of Information & Computer Sciences
140 Governors Drive
University of Massachusetts
Amherst, MA 01003-9264 USA
| Email: | |
| Office: | 302 |
| Phone: | +1-413-577-0233 |
| Fax: | +1-413-545-1249 |
- Our paper on using LLMs to divide and conquer formal verification problems was accepted to ICSE 2026!
- Our paper on provably managing the repercussions of machine learning was accepted to NeurIPS 2025!
- Yuriy joined Cyberonix as a software expert witness consultant.
- Our paper on how visualization affects comprehension and trust of machine learning accepted to VIS'25!
- Our ESEC/FSE'15 paper on overfitting in automated program repair won an Test of Time Honorable Mention Award at FSE 2025!
- Our ESEC/FSE'15 paper on overfitting in automated program repair won an Test of Time Honorable Mention Award at FSE 2025!
- Our ICSE'25 paper on using LLMs for formal verification won an ACM SIGSOFT Distinguished Paper Award!
- Yuriy elevated to IEEE Fellow!
- Our work on using LLMs to synthesize formal verification proofs published at ICSE 2025.
- Our work on using reinforcement rearning to automate formal verification published at ICSE 2025.
- Our work on attack-resistent image watermarking published at NeurIPS 2024.
- Our work on efficient fine-tuning of LLMs on egde networks published at NeurIPS 2024.
- Our work on whether automated program repair helps developers debug published at ICSE 2024.
- Our work on using large language models to synthesize proofs of mathematical theorems published at ESEC/FSE 2023 and wins an ACM SIGSOFT Distinguished Paper Award! IEEE Spectrum article.
- Our work on understanding how bias affects people's trust published at VIS 2023.
- Manish started a job as an Assistant Professor at Oregon State University!
- Emily started a job as a postdoc at University of California San Diego!
- Manish's and Yuriy's work on using tests and bug reports, together, to improve automated program repair published at ICSE 2023. LASER had a total of 6 papers presented at ICSE 2023, including work on making it easier for software engineers to build systems with fair machine learning and automating formal verification.
- Our work on understing developers published in TOSEM, presented at ICSE 2023.
- Yuriy received a $616K NSF grant on automating formal verification!
- Our work on using identifiers to improve proof synthesis for formal verification published at TOPLAS. Presented at PLDI 2023.
- Yuriy receives a $40K Dolby gift for studying effects of bias in machine learning.
- Yuriy gave a keynote address at MaLTeSQuE 2022.
- Emily's and Yuriy's work on diversity-driven automated formal verification published at ICSE 2022 and wins an ACM SIGSOFT Distinguished Paper Award!
- Google gifts $50,000 for work on mitigating bias in models of ad preferences.
- Yuriy and Phil receive a Google Inclusion Research Award.
- Yuriy and Phil receive a Facebook Building Tools to Enhance Transparency in Fairness and Privacy gift.
- Yuriy receives an Amazon Research Award with $40K funding and $20K AWS credit to support formal verification.
- Yuriy promoted to Professor.
- Alex Sanchez-Stern joins UMass as a postdoctoral researcher!
- Yuriy received the 2021 IEEE Computer Society TCSE New Directions Award.
- Yixue Zhao joins UMass as a CI Fellow postdoctoral researcher!
- Fully-automated formal verification paper accepted to OOPSLA 2020: video.
- Yuriy delivers the ICSSP/ICSSE 2020 Keynote address: video.
- Distributed, privacy-enforcing paper wins SEAMS 2020 Most Influential Paper award! video
- Causal testing paper accepted to ICSE 2020.
- Yuriy promoted to ACM Distinguished Member.
- Safety and fairness guarantees in machine learning paper published in Science.
- Quality of automated program repair paper accepted to IEEE TSE.
- Visualization for system understanding paper accepted to ACM TOSEM.
- Serverless computing paper published at OOPSLA 2019 and is awarded an ACM SIGPLAN Distinguished Paper Award.
- Google gifts $50,000 for work on detecting bias in ads.
- Fair bandits paper published at NeurIPS 2019. Read Fortune summary.
- Automated program repair paper accepted to IEEE TSE.
- Oracle labs gifts $100,000 for work on fairness in rankings.
- Test generation from natural language specifications paper published at ICSE 2019.
- Software fairness paper and demo published at ESEC/FSE 2018.
- Security usability paper published at SOUPS 2018.
- Double blind viewpoint published in Communications of the ACM. News coverage.
- Repair of hard and important bugs paper published in Empirical Software Engineering and presented at ICSE 2018.
- Recovering design decisions paper published in ICSA 2018.
- Our fairness testing paper was the 5th most downloaded SE article in October'17.
- Fairness testing in the news:
EnterpriseTech, Bloomberg, GCN, FastCompany Co.Design, ACM News, MIT TR Download, UMass. - Automated repair paper published in ASE 2017.
- Fairness Testing paper published in ESEC/FSE 2017 and is awarded an ACM SIGSOFT Distinguished Paper Award.
- NSF funds grant on software fairness testing.
- Yuriy promoted to Associate Professor with tenure.
- Yuriy promoted to Senior Member of both the ACM and the IEEE.
- Yuriy receives the UMass College of Information and Computer Science Outstanding Teacher Award.
- Yuriy receives a Lilly Fellowship for Teaching Excellence.
- Collaborative Design paper published in ICSA 2017 and is awarded the Best Paper Award!.
- Constraint-Aware Resource Scheduling paper published in IEEE Transactions on Systems, Man, and Cybernetics: Systems.
- Behavioral Execution Comparison paper published in ICST 2017.
- Dr. Seung Yeob Shin successfully defended his dissertation. He started at the University of Luxembourg in Fall'16.
- NSF funds medium grant on improving quality of automated program repair.
- Distributed system debugging paper published in Communications of the ACM.
- Performance-aware modeling tool paper presented at ICSE 2016.
- Eureka! Winter'16 program with local Girls Inc. chapter a success!
- Yuriy receives a 2015 Google Faculty Research Award.
- An independent study finds conflict detection work the most industrially relevant of all research published in the top SE conferences in the last five years.
- Yuriy recognized as a UMass Distinguished Teaching Award finalist.
- Two papers on automated API violation discovery presented at ISSRE 2015.
- NSF funds medium grant on improving developer interfaces.
- “Using Simulation...” published in JSS.
- “Repairing Programs...” presented at ASE 2015.
- “Simplifying Development History...” presented at ASE 2015 short paper track.
- “Is the Cure Worse...” presented at ESEC/FSE 2015.
- “The ManyBugs and IntroClass Benchmarks...” featured as the Spotlight Paper in December 2015 by IEEE TSE.
- “Preventing Data Errors...” presented at ISSTA 2015.
- Yuriy receives an ICSE 2015 Distinguished Reviewer Award.
- “Self-Adapting Reliability...” published in IEEE TSE.
- “Reducing feedback delay...” published in IEEE TSE.
- Yuriy receives the NSF CAREER award!
- “Resource Specification...” presented at FASE 2015.
- “Using declarative specification...” published in IEEE TSE.
- “Behavioral Resource-Aware...” presented at ASE 2014.
- “Automatic Mining...” presented at FSE 2014.
- “The Plastic Surgery Hypothesis” presented at FSE 2014.
- Yuriy receives the 2014 Microsoft Research Software Engineering Innovation Foundation Award.
- “Inferring Models of Concurrent...” presented at ICSE 2014.
- “Mining Precise Performance-Aware...” presented at ICSE NIER 2014.
- Yuriy receives the 2013 IEEE TCSC Young Achiever in Scalable Computing Award.
- “Early Detection...” featured as the Spotlight Paper in October 2013 by IEEE TSE.
- “Making Offline Analyses Continuous” presented at ESEC/FSE 2013.
- “Data Debugging... ” presented at ESEC/FSE NI 2013.
- Future of Software Engineering 2013 took place in July 2013.
- “Unifying FSM-Inference...” presented at ICSE 2013.
- “Entrusting Private Compu...” published in IEEE TDSC.
- “Understanding Regression...” presented at ICSE NIER 2013.
- “Speculative Analysis...” presented at OOPSLA 2012.
- “Proactive Detection of...” published in ESEC/FSE 2011 and is awarded an ACM SIGSOFT Distinguished Paper Award. Watch the talk.
I have previously worked with Prof. Leonard Adleman at the USC Laboratory for Molecular Science and with Prof. Michael D. Ernst at the MIT Computer Science and Artificial Intelligence Laboratory Program Analysis Group.
My research aims to improve how we build software systems, focusing on proving system correctness, mitigating bias, and enabling self-adaption and self-repair. I co-direct the LASER and PLASMA laboratories.
|
My lab's research focuses on high-risk, high-impact problems, with the aim of
fundamentally improving how engineers build systems. Sometimes we fail.
Sometimes we succeed and make a difference in industry, academia, or both. Our work has received a Microsoft Research Software Engineering Innovation Foundation Award, a Google Inclusion Research Award, an Amazon Research Award, a Google Faculty Research Award, and an NSF CAREER Award, as well as five ACM SIGSOFT and SIGPLAN Distinguished Paper Awards and a Best Paper Award, and has been funded by the NSF, DARPA, IARPA, Amazon, Dolby, Google, Kosa.ai, Microsoft, Meta, and Oracle. |
Automating formal verificationFormal verification—proving the correctness of software—is one of the most effective ways of improving software quality. But, despite significant help from interactive theorem provers and automation tools such as hammers, writing the required proofs is an incredibly difficult, time consuming, and error prone manual process. My work has pioneered ways to use natural language processing to synthesize formal verification proofs. Automating proof synthesis can drastically reduce costs of formal verification and improve software quality. The unique nature of formal verification allows us to combine multiple models to fully automatically prove 33.8% of formal verification theorems in Coq (ICSE'22 Distinguished Paper Award), and use large language models to synthesize guaranteed-correct proofs for 65.7% of mathematical theorems in Isabelle (ESEC/FSE'23 Distinguished Paper Award). |
Provably fair and safe software
|
 Today, increasingly more software uses artificial intelligence.
Unfortunately, recent investigations have shown that such systems can
discriminate and be unsafe for humans. My work identified that numerous
challenges in this space are fundamentally software engineering challenges,
Today, increasingly more software uses artificial intelligence.
Unfortunately, recent investigations have shown that such systems can
discriminate and be unsafe for humans. My work identified that numerous
challenges in this space are fundamentally software engineering challenges,
Trust in machine learningIncreasingly, software systems use machine learning. Whether users understand how this technology functions can fundamentally affect their trust in these systems. We study how aspects of machine learning, such as precision and bias, affect people's perception and trust, and how explainability techniques can better educate users, engineers, and policymakers into making better, evidence-based decisions about machine learning. Our findings include that bias affects men and women differently when making trust-based decisions, and that visualization design choices have a significant impact on bias perception, and on the resulting trust. |
High-quality automated program repair
|
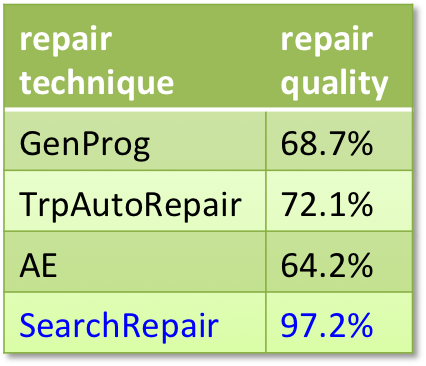 Software bugs are incredibly costly, but so is software debugging, as more
new bugs are reported every day than developers can handle. Automatic
program repair has the potential to significantly reduce time and cost of
debugging. But our work has shown that such techniques can often
Software bugs are incredibly costly, but so is software debugging, as more
new bugs are reported every day than developers can handle. Automatic
program repair has the potential to significantly reduce time and cost of
debugging. But our work has shown that such techniques can often
Proactive detection of collaboration conflicts
|
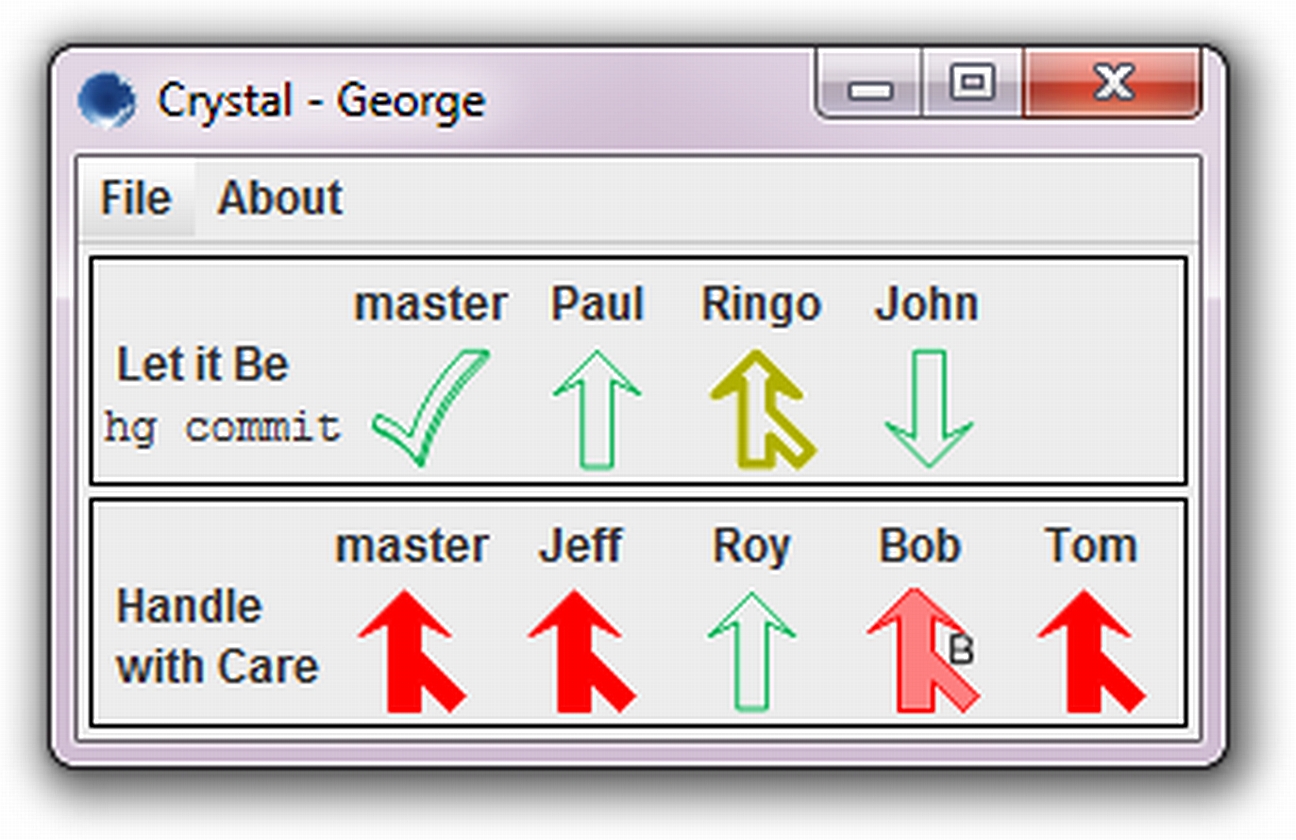 One of my most impactful projects, in terms of influence on industry and
others' research, has been work on collaborative development. Using our
speculative analysis technology, we built
One of my most impactful projects, in terms of influence on industry and
others' research, has been work on collaborative development. Using our
speculative analysis technology, we built
Privacy preservation in distributed computation
|
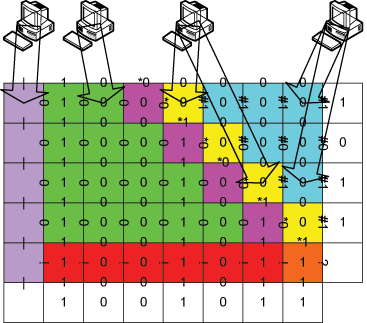 My email, my taxes, my research, my medical records are all on the cloud.
How do I distribute computation onto untrusted machines while making sure
those machines cannot read my private data?
My email, my taxes, my research, my medical records are all on the cloud.
How do I distribute computation onto untrusted machines while making sure
those machines cannot read my private data?
Automatically inferring precise models of system behaviorDebugging and improving systems requires understanding their behavior. Using source code and execution logs to understand behavior is a daunting task. We develop tools to aid understanding and development tasks, many of which involve automatically inferring a human-readable FSM-based behavioral model. This project is or has been funded by the NSF, Google, and Microsoft Research. We have shown that the inferred models can be used to detect software vulnerabilities (read) and are currently building model-based tools to improve test suite quality at Google. |
|
|
|
|
|
|
|
|

Reliability through smart redundancy
|
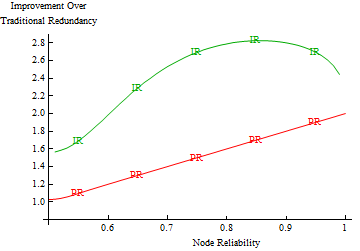 One of the most common ways of achieving system
reliability is through redundancy. But how can we ensure
we are using the resources in a smart way? Can we
guarantee that we are squeezing the most reliability
possible out of our available resources? A new technique
called smart redundancy says we can! Read:
One of the most common ways of achieving system
reliability is through redundancy. But how can we ensure
we are using the resources in a smart way? Can we
guarantee that we are squeezing the most reliability
possible out of our available resources? A new technique
called smart redundancy says we can! Read:
Self-adaptive systems
|
 Self-adaptive systems are capable of handling runtime changes in
requirements and the environment. When something goes wrong, self-adaptive
systems can recover on-the-fly. Building such systems poses many challenge
as developers often have to design the system without knowing all
requirements changes and potential attacks that could take place. Read
about the challenges of and a research roadmap for self-adaptive systems
Self-adaptive systems are capable of handling runtime changes in
requirements and the environment. When something goes wrong, self-adaptive
systems can recover on-the-fly. Building such systems poses many challenge
as developers often have to design the system without knowing all
requirements changes and potential attacks that could take place. Read
about the challenges of and a research roadmap for self-adaptive systems
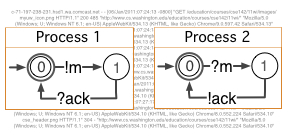
Bug cause analysisWhen regression tests break, can the information about the latest changes help find the cause of the failure? The cause might be a bug in recently added code, or it could instead be in old code that wasn't exercised in a fault-revealing way until now. Considering the minimal test-failing sets of recent changes, and maximal test-passing sets of those changes can identify surprises about the failure's cause. Read: Understanding Regression Failures through Test-Passing and Test-Failing Code Changes. |
DNA Self-Assembly
|
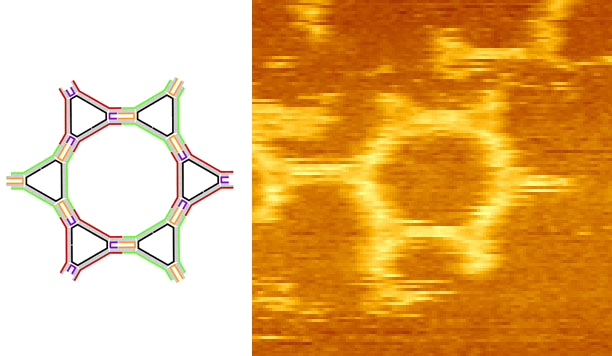 How do simple objects self-assemble to form complex
structures? Answering that question can lead to
understanding interactions of objects as simple as atoms
and as complex as software systems. Studying mathematical
models of molecular interactions and gaining control over
nanoscale DNA structures, begins to understand this space.
Read: (theory)
How do simple objects self-assemble to form complex
structures? Answering that question can lead to
understanding interactions of objects as simple as atoms
and as complex as software systems. Studying mathematical
models of molecular interactions and gaining control over
nanoscale DNA structures, begins to understand this space.
Read: (theory)
The fault-invariant classifier
|
 Can the wealth of knowledge and examples of bugs make it
easier to discover unknown, latent bugs in new software?
For example, if I have access to bugs, and bug fixes in
Windows 7, can I find bugs in Windows 8 before it ships?
Machine learning makes this possible for certain classes
of often-repeated bugs. Read:
Can the wealth of knowledge and examples of bugs make it
easier to discover unknown, latent bugs in new software?
For example, if I have access to bugs, and bug fixes in
Windows 7, can I find bugs in Windows 8 before it ships?
Machine learning makes this possible for certain classes
of often-repeated bugs. Read: | 2026 | |
| [ICML] | Kunjal Panchal, Sunav Choudhary, Yuriy Brun, and Hui Guan, Memory Savings at What Cost? A Study of Alternatives to Backpropagation, in Proceedings of the 43rd International Conference on Machine Learning (ICML), 2026. |
| [FAccT] | Aimen Gaba, Emily Wall, Os Keyes, Yuriy Brun, Kyle Wm Hall, and Cindy Xiong Bearfield, A Gender Diverse Perspective of Bias in Large Language Models, in Proceedings of the 9th ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2026, pp. 1312–1339. |
| [ICSE] | Zhanna Kaufman, Emily First, Alex Sanchez-Stern, Kyle Thompson, Sorin Lerner, and Yuriy Brun, ProofCoop: Collaborative Automated Formal Verification, in Proceedings of the 48th International Conference on Software Engineering (ICSE), 2026, pp. 1339–1352. |
| [ICSE] | Saketh Ram Kasibatla, Arpan Agrawal, Yuriy Brun, Sorin Lerner, Talia Ringer, and Emily First, Cobblestone: A Divide-and-Conquer Approach for Automating Formal Verification, in Proceedings of the 48th International Conference on Software Engineering (ICSE), 2026, pp. 714–726. |
| [TOSEM] | Yuriy Brun, Saikat Chakraborty, Claire Le Goues, Corina Păsăreanu, and Adish Singla, Automatically Engineering Trusted Software: A Research Roadmap, ACM Transactions on Software Engineering and Methodology (TOSEM), 2026. |
| [TVCG] | Zhanna Kaufman, Madeline Endres, Cindy Xiong Bearfield, and Yuriy Brun, Your Model Is Unfair, Are You Even Aware? Inverse Relationship Between Comprehension and Trust in Explainability Visualizations of Biased ML Models, IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 32, no. 1, 2026, pp. 637–647. |
| 2025 | |
| [NeurIPS] | Aline Weber, Blossom Metevier, Yuriy Brun, Philip S. Thomas, and Bruno Castro da Silva, Beyond Prediction: Managing the Repercussions of Machine Learning Applications, in Proceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 38, 2025. |
| [ICSE] | Kyle Thompson, Nuno Saavedra, Pedro Carrott, Kevin Fisher, Alex Sanchez-Stern, Yuriy Brun, João F. Ferreira, Sorin Lerner, and Emily First, Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification, in Proceedings of the 47th International Conference on Software Engineering (ICSE), 2025, pp. 347–359. |
| [ICSE] | Alex Sanchez-Stern, Abhishek Varghese, Zhanna Kaufman, Dylan Zhang, Talia Ringer, and Yuriy Brun, QEDCartographer: Automating Formal Verification Using Reward-Free Reinforcement Learning, in Proceedings of the 47th International Conference on Software Engineering (ICSE), 2025, pp. 307–320. |
| 2024 | |
| [NeurIPS] | Lijun Zhang, Xiao Liu, Antoni Viros i Martin, Cindy Xiong Bearfield, Yuriy Brun, and Hui Guan, Attack-Resilient Image Watermarking Using Stable Diffusion, in Proceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 37, 2024, pp. 38480–38507. |
| [NeurIPS] | Kunjal Panchal, Nisarg Parikh, Sunav Choudhary, Lijun Zhang, Yuriy Brun, and Hui Guan, Thinking Forward: Memory-Efficient Federated Finetuning of Language Models, in Proceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 37, 2024, pp. 69069–69119. |
| [ICSE] | Hadeel Eladawy, Claire Le Goues, and Yuriy Brun, Automated Program Repair, What Is It Good For? Not Absolutely Nothing!, in Proceedings of the 46th International Conference on Software Engineering (ICSE), 2024, pp. 1017–1029. |
| [TVCG] | Aimen Gaba, Zhanna Kaufman, Jason Cheung, Marie Shvakel, Kyle Wm Hall, Yuriy Brun, and Cindy Xiong Bearfield, My Model is Unfair, Do People Even Care? Visual Design Affects Trust and Perceived Bias in Machine Learning, IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 30, no. 1, January 2024, pp. 327–337. |
| 2023 | |
| [ESEC/FSE] | Emily First, Markus Rabe, Talia Ringer, and Yuriy Brun, Baldur: Whole-Proof Generation and Repair with Large Language Models, in Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2023, pp. 1229–1241 (ACM SIGSOFT Distinguished Paper Award). |
| [TOPLAS] | Alex Sanchez-Stern, Emily First, Timothy Zhou, Zhanna Kaufman, Yuriy Brun, and Talia Ringer, Passport: Improving Automated Formal Verification Using Identifiers, ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 45, no. 2, June 2023, pp. 12:1–12:30. |
| [ICSE Demo] | Austin Hoag, James E. Kostas, Bruno Castro da Silva, Philip S. Thomas, and Yuriy Brun, Seldonian Toolkit: Building Software with Safe and Fair Machine Learning, in Proceedings of the Demonstrations Track at the 45th International Conference on Software Engineering (ICSE), 2023, pp. 107–111. |
| [ICSE Demo] | Arpan Agrawal, Emily First, Zhanna Kaufman, Tom Reichel, Shizhuo Zhang, Timothy Zhou, Alex Sanchez-Stern, Talia Ringer, and Yuriy Brun, Proofster: Automated Formal Verification, in Proceedings of the Demonstrations Track at the 45th International Conference on Software Engineering (ICSE), 2023, pp. 26–30. |
| [ICSE Demo] | Saghar Talebipour, Hyojae Park, Kesina Baral, Leon Yee, Safwat Ali Khan, Kevin Moran, Yuriy Brun, Nenad Medvidovic, and Yixue Zhao, AVGUST: A Tool for Generating Usage-Based Tests from Videos of App Executions, in Proceedings of the Demonstrations Track at the 45th International Conference on Software Engineering (ICSE), 2023, pp. 83–87. |
| [ICSE SEIP] | Manish Motwani and Yuriy Brun, Understanding Why and Predicting When Developers Adhere to Code-Quality Standards, in Proceedings of the Software Engineering in Practice Track at the 45th International Conference on Software Engineering (ICSE SEIP), 2023, pp. 432–444. |
| [ICSE] | Manish Motwani and Yuriy Brun, Better Automatic Program Repair by Using Bug Reports and Tests Together, in Proceedings of the 45th International Conference on Software Engineering (ICSE), 2023, pp. 1229–1241. |
| [TOSEM] | Yuriy Brun, Tian Lin, Jessie Elise Somerville, Elisha M. Myers, and Natalie Ebner, Blindspots in Python and Java APIs Result in Vulnerable Code, ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 32, no. 3, April 2023, pp. 76:1–76:31. |
| [EJDP] | Brittany Johnson, Jesse Bartola, Rico Angell, Sam Witty, Stephen J. Giguere, and Yuriy Brun, Fairkit, Fairkit, on the Wall, Who's the Fairest of Them All? Supporting Data Scientists in Training Fair Models, EURO Journal on Decision Processes, vol. 11, 2023. |
| 2022 | |
| [MaLTeSQuE Keynote] | Yuriy Brun, The Promise and Perils of Using Machine Learning When Engineering Software (Keynote Paper), in Proceedings of the International Workshop on Machine Learning Techniques for Software Quality Evaluation (MaLTeSQuE), 2022, pp. 1–4. |
| [ESEC/FSE] | Yixue Zhao, Saghar Talebipour, Kesina Baral, Hyojae Park, Leon Yee, Safwat Ali Khan, Yuriy Brun, Nenad Medvidovic, and Kevin Moran, Avgust: Automating Usage-Based Test Generation from Videos of App Executions, in Proceedings of the 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2022, pp. 421–433. |
| [ICSE Demo] | Brittany Johnson and Yuriy Brun, Fairkit-learn: A Fairness Evaluation and Comparison Toolkit, in Proceedings of the Demonstrations Track at the 44th International Conference on Software Engineering (ICSE), 2022, pp. 70–74. |
| [ICSE] | Emily First and Yuriy Brun, Diversity-Driven Automated Formal Verification, in Proceedings of the 44th International Conference on Software Engineering (ICSE), 2022, pp. 749–761 (ACM SIGSOFT Distinguished Paper Award). |
| [ICLR] | Stephen Giguere, Blossom Metevier, Yuriy Brun, Bruno Castro da Silva, Philip S. Thomas, and Scott Niekum, Fairness Guarantees under Demographic Shift, in Proceedings of the 10th International Conference on Learning Representations (ICLR), 2022. |
| [TSE] | Manish Motwani, Mauricio Soto, Yuriy Brun, and René Just, Quality of Automated Program Repair on Real-World Defects, IEEE Transactions on Software Engineering (TSE), vol. 48, no. 2, February 2022, pp. 637–661. |
| 2021 | |
| [TSE] | Afsoon Afzal, Manish Motwani, Kathryn T. Stolee, and Yuriy Brun, SOSRepair: Expressive Semantic Search for Real-World Program Repair, IEEE Transactions on Software Engineering (TSE), vol. 47, no. 10, October 2021, pp. 2162–2181. |
| 2020 | |
| [DLS] | Donald Pinckney, Arjun Guha, and Yuriy Brun, Wasm/k: Delimited Continuations for WebAssembly, in Proceedings of the ACM SIGPLAN International Symposium on Dynamic Languages (DLS), 2020, pp. 16–28. |
| [OOPSLA] | Emily First, Yuriy Brun, and Arjun Guha, TacTok: Semantics-Aware Proof Synthesis, Proceedings of the ACM on Programming Languages (PACMPL) Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA) issue, vol. 4, November 2020, pp. 231:1–231:31. |
| [ESEC/FSE] | Arman Shahbazian, Suhrid Karthik, Yuriy Brun, and Nenad Medvidovic, eQual: Informing Early Design Decisions, in Proceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2020, pp. 1039–1051. |
| [ICSE] | Brittany Johnson, Yuriy Brun, and Alexandra Meliou, Causal Testing: Understanding Defects' Root Causes, in Proceedings of the 42nd International Conference on Software Engineering (ICSE), 2020, pp. 87–99 (ACM SIGSOFT Distinguished Artifact Award). |
| [TOSEM] | Ivan Beschastnikh, Perry Liu, Albert Xing, Patty Wang, Yuriy Brun, and Michael D. Ernst, Visualizing distributed system executions, ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 29, no. 2, March 2020, pp. 9:1–9:38. |
| 2019 | |
| [NeurIPS] | Blossom Metevier, Stephen Giguere, Sarah Brockman, Ari Kobren, Yuriy Brun, Emma Brunskill, and Philip S. Thomas, Offline Contextual Bandits with High Probability Fairness Guarantees, in Proceedings of the 33rd Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 32, 2019, pp. 14893–14904. |
| [OOPSLA] | Abhinav Jangda, Donald Pinckney, Yuriy Brun, and Arjun Guha, Formal Foundations of Serverless Computing, Proceedings of the ACM on Programming Languages (PACMPL) Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA) issue, vol. 3, October 2019, pp. 149:1–149:26 (ACM SIGPLAN Distinguished Paper Award). |
| [ICSE] | Manish Motwani and Yuriy Brun, Automatically Generating Precise Oracles from Structured Natural Language Specifications, in Proceedings of the 41st International Conference on Software Engineering (ICSE), 2019, pp. 188–199. |
| [Science] | Philip S. Thomas, Bruno Castro da Silva, Andrew G. Barto, Stephen Giguere, Yuriy Brun, and Emma Brunskill, Preventing Undesirable Behavior of Intelligent Machines, Science, vol. 366, no. 6468, 22 November 2019, pp. 999–1004. |
| 2018 | |
| [ESEC/FSE NIER] | Yuriy Brun and Alexandra Meliou, Software Fairness, in Proceedings of the New Ideas and Emerging Results Track at the 26th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2018, pp. 754–759. |
| [ESEC/FSE Demo] | Rico Angell, Brittany Johnson, Yuriy Brun, and Alexandra Meliou, Themis: Automatically Testing Software for Discrimination, in Proceedings of the Demonstrations Track at the 26th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2018, pp. 871–875. |
| [EMSE] | Manish Motwani, Sandhya Sankaranarayanan, René Just, and Yuriy Brun, Do Automated Program Repair Techniques Repair Hard and Important Bugs?, Empirical Software Engineering (EMSE), vol. 23, no. 5, October 2018, pp. 2901–2947. |
| [TSMC] | Seung Yeob Shin, Yuriy Brun, Hari Balasubramanian, Philip L. Henneman, and Leon J. Osterweil, Discrete-Event Simulation and Integer Linear Programming for Constraint-Aware Resource Scheduling, IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 48, no. 9, September 2018, pp. 1578–1593. |
| [SOUPS] | Daniela Seabra Oliveira, Tian Lin, Muhammad Sajidur Rahman, Rad Akefirad, Donovan Ellis, Eliany Perez, Rahul Bobhate, Lois A. DeLong, Justin Cappos, Yuriy Brun, and Natalie C. Ebner, API Blindspots: Why Experienced Developers Write Vulnerable Code, in Proceedings of the USENIX Symposium on Usable Privacy and Security (SOUPS), 2018, pp. 315–328. |
| [CACM] | Claire Le Goues, Yuriy Brun, Sven Apel, Emery Berger, Sarfraz Khurshid, and Yannis Smaragdakis, Effectiveness of Anonymization in Double-Blind Review, Communications of the ACM, vol. 61, no. 6, June 2018, pp. 34–37. |
| [FairWare] | Y. Brun, B. Johnson, A. Meliou, Eds., Proceedings of the IEEE/ACM International Workshop on Software Fairness (FairWare), 2018. |
| [FairWare] | Yuriy Brun, Brittany Johnson, and Alexandra Meliou, Message from the FairWare 2018 Chairs, in Proceedings of the IEEE/ACM International Workshop on Software Fairness, 2018. |
| [ICSA] | Arman Shahbazian, Youn Kyu Lee, Duc Le, Yuriy Brun, and Nenad Medvidovic, Recovering Architectural Design Decisions, in Proceedings of the IEEE International Conference on Software Architecture (ICSA), 2018, pp. 95–104. |
| [ICSE Journal First] | Manish Motwani, Sandhya Sankaranarayanan, René Just, and Yuriy Brun, Do Automated Program Repair Techniques Repair Hard and Important Bugs?, in Proceedings of the Journal First Track at the International Conference on Software Engineering (ICSE), 2018, pp. 25. |
| [ICSE Poster] | Arman Shahbazian, Youn Kyu Lee, Yuriy Brun, and Nenad Medvidovic, Poster: Making Well-Informed Software Design Decisions, in Proceedings of the Poster Track at the International Conference on Software Engineering (ICSE), 2018, pp. 262–263. |
| [IEEE Software] | Jae young Bang, Yuriy Brun, and Nenad Medvidovic, Collaborative Design Conflicts: Costs and Solutions, IEEE Software, vol. 35, no. 6, November/December 2018, pp. 25–31. |
| [Chapter] | Rogério de Lemos, David Garlan, Carlo Ghezzi, Holger Giese, Jesper Andersson, Marin Litoiu, Bradley Schmerl, Danny Weyns, Luciano Baresi, Nelly Bencomo, Yuriy Brun, Javier Camara, Radu Calinescu, Myra B. Cohen, Alessandra Gorla, Vincenzo Grassi, Lars Grunske, Paola Inverardi, Jean-Marc Jezequel, Sam Malek, Raffaela Mirandola, Marco Mori, Hausi A. Müller, Romain Rouvoy, Cecilia M. F. Rubira, Eric Rutten, Mary Shaw, Giordano Tamburrelli, Gabriel Tamura, Norha M. Villegas, Thomas Vogel, and Franco Zambonelli, Software Engineering for Self-Adaptive Systems: Research Challenges in the Provision of Assurances, in Software Engineering for Self-Adaptive Systems III, R. d. Lemos et al., Eds., Springer, 2018, pp. 3–30. |
| [Chapter] | Bradley Schmerl, Jesper Andersson, Thomas Vogel, Myra B. Cohen, Cecilia M. F. Rubira, Yuriy Brun, Alessandra Gorla, Franco Zambonelli, and Luciano Baresi, Challenges in Composing and Decomposing Assurances for Self-Adaptive Systems, in Software Engineering for Self-Adaptive Systems III. Assurances, R. d. Lemos et al., Eds., Springer, 2018, pp. 64–89. |
| 2017 | |
| [TSE] | Claire Le Goues, Yuriy Brun, Stephanie Forrest, and Westley Weimer, Clarifications on the Construction and Use of the ManyBugs Benchmark, IEEE Transactions on Software Engineering (TSE), comment paper, vol. 43, no. 11, November 2017, pp. 1089–1090. |
| [ESEC/FSE] | Sainyam Galhotra, Yuriy Brun, and Alexandra Meliou, Fairness Testing: Testing Software for Discrimination, in Proceedings of the 11th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2017, pp. 498–510 (ACM SIGSOFT Distinguished Paper Award). |
| [ICSA] | Jae young Bang, Yuriy Brun, and Nenad Medvidovic, Continuous Analysis of Collaborative Design, in Proceedings of the IEEE International Conference on Software Architecture (ICSA), 2017, pp. 97–106 (Best Paper Award). |
| [ICST] | Qianqian Wang, Yuriy Brun, and Alessandro Orso, Behavioral Execution Comparison: Are Tests Representative of Field Behavior?, in Proceedings of the 10th IEEE International Conference on Software Testing, Verification, and Validation (ICST), 2017, pp. 321–332. |
| [ASE] | Aaron Weiss, Arjun Guha, and Yuriy Brun, Tortoise: Interactive System Configuration Repair, in Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), 2017, pp. 625–636. |
| 2016 | |
| [CACM] | Ivan Beschastnikh, Patty Wang, Yuriy Brun, and Michael D. Ernst, Debugging Distributed Systems, Communications of the ACM, vol. 59, no. 8, August 2016, pp. 32–37. |
| [SEHS] | Seung Yeob Shin, Yuriy Brun, and Leon J. Osterweil, Specification and Analysis of Human-Intensive System Resource-Utilization Policies, in Proceedings of the 8th International Workshop on Software Engineering in Healthcare Systems (SEHS), 2016, pp. 8–14. |
| [ICSE Demo] | Tony Ohmann, Ryan Stanley, Ivan Beschastnikh, and Yuriy Brun, Visually Reasoning about System and Resource Behavior, in Proceedings of the Demonstrations Track of the 38th International Conference on Software Engineering (ICSE Demo), 2016, pp. 601–604. |
| [ACM Queue] | Ivan Beschastnikh, Patty Wang, Yuriy Brun, and Michael D. Ernst, Debugging Distributed Systems, ACM Queue, vol. 14, no. 2, March/April 2016, pp. 91–110. |
| 2015 | |
| [JSS] | Jie Chen, Xiwei Xu, Leon J. Osterweil, Liming Zhu, Yuriy Brun, Len Bass, Junchao Xiao, Mingshu Li, and Qing Wang, Using Simulation to Evaluate Error Detection Strategies: A Case Study of Cloud-Based Deployment Processes, Journal of Systems and Software, vol. 110, December 2015, pp. 205–221. |
| [TSE] | Claire Le Goues, Neal Holtschulte, Edward K. Smith, Yuriy Brun, Premkumar Devanbu, Stephanie Forrest, and Westley Weimer, The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 12, December 2015, pp. 1236–1256. |
| [ASE] | Kivanç Muşlu, Luke Swart, Yuriy Brun, and Michael D. Ernst, Simplifying Development History Information Retrieval via Multi-Grained Views, in Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015, pp. 697–702. |
| [ASE] | Yalin Ke, Kathryn T. Stolee, Claire Le Goues, and Yuriy Brun, Repairing Programs with Semantic Code Search, in Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015, pp. 295–306. |
| [ISSRE] | Robert J. Walls, Yuriy Brun, Marc Liberatore, and Brian Neil Levine, Discovering Specification Violations in Networked Software Systems, in Proceedings of the 26th IEEE International Symposium on Software Reliability Engineering (ISSRE), 2015, pp. 496–506. |
| [ISSRE] | Jeff Rasley, Eleni Gessiou, Tony Ohmann, Yuriy Brun, Shriram Krishnamurthi, and Justin Cappos, Detecting Latent Cross-Platform API Violations, in Proceedings of the 26th IEEE International Symposium on Software Reliability Engineering (ISSRE), 2015, pp. 484–495. |
| [JoNA] | Philip L. Henneman, Seung Yeob Shin, Yuriy Brun, Hari Balasubramanian, Fidela Blank, and Leon J. Osterweil, Using Computer Simulation to Study Nurse-to-Patient Ratios in an Emergency Department, The Journal of Nursing Administration, vol. 45, no. 11, November 2015, pp. 551–556. |
| [ESEC/FSE] | Edward K. Smith, Earl Barr, Claire Le Goues, and Yuriy Brun, Is the Cure Worse than the Disease? Overfitting in Automated Program Repair, in Proceedings of the 10th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2015, pp. 532–543 (FSE 2025 Test of Time Honorable Mention Award). |
| [TSE] | Yuriy Brun, Jae young Bang, George Edwards, and Nenad Medvidovic, Self-Adapting Reliability in Distributed Software Systems, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 8, August 2015, pp. 764–780. |
| [TSE] | Kivanç Muşlu, Yuriy Brun, Michael D. Ernst, and David Notkin, Reducing feedback delay of software development tools via continuous analyses, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 8, August 2015, pp. 745–763. |
| [ISSTA] | Kivanç Muşlu, Yuriy Brun, and Alexandra Meliou, Preventing Data Errors with Continuous Testing, in Proceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), 2015, pp. 373–384. |
| [FASE] | Seung Yeob Shin, Yuriy Brun, Leon J. Osterweil, Hari Balasubramanian, and Philip L. Henneman, Resource Specification for Prototyping Human-Intensive Systems, in Proceedings of the 18th International Conference on Fundamental Approaches to Software Engineering (FASE), 2015, pp. 332–346. |
| [TSE] | Ivan Beschastnikh, Yuriy Brun, Jenny Abrahamson, Michael D. Ernst, and Arvind Krishnamurthy, Using declarative specification to improve the understanding, extensibility, and comparison of model-inference algorithms, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 4, April 2015, pp. 408–428. |
| 2014 | |
| [FSE] | Earl T. Barr, Yuriy Brun, Premkumar Devanbu, Mark Harman, and Federica Sarro, The Plastic Surgery Hypothesis, in Proceedings of the 22nd ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE), 2014, pp. 306–317. |
| [FSE] | Ivo Krka, Yuriy Brun, and Nenad Medvidovic, Automatic Mining of Specifications from Invocation Traces and Method Invariants, in Proceedings of the 22nd ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE), 2014, pp. 178–189. |
| [ASE] | Tony Ohmann, Michael Herzberg, Sebastian Fiss, Armand Halbert, Marc Palyart, Ivan Beschastnikh, and Yuriy Brun, Behavioral Resource-Aware Model Inference, in Proceedings of the 29th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2014, pp. 19–30. |
| [ICSE Poster] | Jenny Abrahamson, Ivan Beschastnikh, Yuriy Brun, and Michael D. Ernst, Shedding Light on Distributed System Executions, in Proceedings of the Poster Track at the International Conference on Software Engineering (ICSE), 2014, pp. 598–599. |
| [ICSE NIER] | Tony Ohmann, Kevin Thai, Ivan Beschastnikh, and Yuriy Brun, Mining Precise Performance-Aware Behavioral Models from Existing Instrumentation, in Proceedings of the New Ideas and Emerging Results Track at the International Conference on Software Engineering (ICSE), 2014, pp. 484–487. |
| [ICSE] | Ivan Beschastnikh, Yuriy Brun, Michael D. Ernst, and Arvind Krishnamurthy, Inferring Models of Concurrent Systems from Logs of their Behavior with CSight, in Proceedings of the 36th International Conference on Software Engineering (ICSE), 2014, pp. 468–479. |
| 2013 | |
| [TSE] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Early Detection of Collaboration Conflicts and Risks, IEEE Transactions on Software Engineering (TSE), vol. 39, no. 10, October 2013, pp. 1358–1375. |
| [ESEC/FSE NI] | Kivanç Muşlu, Yuriy Brun, and Alexandra Meliou, Data Debugging with Continuous Testing, in Proceedings of the New Ideas Track at the 9th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2013, pp. 631–634. |
| [ESEC/FSE] | Kivanç Muşlu, Yuriy Brun, Michael D. Ernst, and David Notkin, Making Offline Analyses Continuous, in Proceedings of the 9th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2013, pp. 323–333. |
| [SEHC] | Seung Yeob Shin, Hari Balasubramanian, Yuriy Brun, Philip L. Henneman, and Leon J. Osterweil, Resource Scheduling through Resource-Aware Simulation of Emergency Departments, in Proceedings of the 5th International Workshop on Software Engineering in Health Care (SEHC), 2013, pp. 64–70. |
| [ICSSP] | Xiang Zhao, Yuriy Brun, and Leon J. Osterweil, Supporting Process Undo and Redo in Software Engineering Decision Making, in Proceedings of the 8th International Conference on Software and System Process (ICSSP), 2013, pp. 56–60. |
| [ICSE NIER] | Roykrong Sukkerd, Ivan Beschastnikh, Jochen Wuttke, Sai Zhang, and Yuriy Brun, Understanding Regression Failures through Test-Passing and Test-Failing Code Changes, in Proceedings of the New Ideas and Emerging Results Track at the 35th International Conference on Software Engineering (ICSE), 2013, pp. 1177–1180. |
| [ICSE] | Ivan Beschastnikh, Yuriy Brun, Jenny Abrahamson, Michael D. Ernst, and Arvind Krishnamurthy, Unifying FSM-inference algorithms through declarative specification, in Proceedings of the 35th International Conference on Software Engineering (ICSE), 2013, pp. 252–261. |
| [TaPP] | Xiang Zhao, Emery R. Boose, Yuriy Brun, Barbara Staudt Lerner, and Leon J. Osterweil, Supporting Undo and Redo in Scientific Data Analysis, in Proceedings of the 5th USENIX Workshop on the Theory and Practice of Provenance (TaPP), 2013. |
| [TDSC] | Yuriy Brun and Nenad Medvidovic, Entrusting Private Computation and Data to Untrusted Networks, IEEE Transactions on Dependable and Secure Computing (TDSC), vol. 10, no. 4, July/August 2013, pp. 225–238. |
| [Chapter] | Yuriy Brun, Ron Desmarais, Kurt Geihs, Marin Litoiu, Antonia Lopes, Mary Shaw, and Mike Smit, A design space for adaptive systems, in Software Engineering for Self-Adaptive Systems II, R. d. Lemos et al., Eds., Springer-Verlag, 2013, pp. 33–50. |
| [Chapter] | Rogério de Lemos, Holger Giese, Hausi A. Müller, Mary Shaw, Jesper Andersson, Luciano Baresi, Basil Becker, Nelly Bencomo, Yuriy Brun, Bojan Cukic, Ron Desmarais, Schahram Dustdar, Gregor Engels, Kurt Geihs, Karl M. Goeschka, Alessandra Gorla, Vincenzo Grassi, Paola Inverardi, Gabor Karsai, Jeff Kramer, Marin Litoiu, Antonia Lopes, Jeff Magee, Sam Malek, Serge Mankovskii, Raffaela Mirandola, John Mylopoulos, Oscar Nierstrasz, Mauro Pezzè, Christian Prehofer, Wilhelm Schäfer, Rick Schlichting, Bradley Schmerl, Dennis B. Smith, João P. Sousa, Gabriel Tamura, Ladan Tahvildari, Norha M. Villegas, Thomas Vogel, Danny Weyns, Kenny Wong, and Jochen Wuttke, Software engineering for self-adaptive systems: A second research roadmap, in Software Engineering for Self-Adaptive Systems II, R. d. Lemos et al., Eds., Springer-Verlag, 2013, pp. 1–32. |
| 2012 | |
| [OOPSLA] | Kivanç Muşlu, Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Speculative Analysis of Integrated Development Environment Recommendations, in Proceedings of the 27th ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA), 2012, pp. 669–682. |
| [TinyToCS] | Jochen Wuttke, Ivan Beschastnikh, and Yuriy Brun, Effects of Centralized and Distributed Version Control on Commit Granularity, Tiny Transactions on Computer Science, vol. 1, September 2012. |
| [WICSA] | George Edwards, Yuriy Brun, and Nenad Medvidovic, Automated analysis and code generation for domain-specific models, in the joint 10th Working IEEE/IFIP Conference on Software Architecture and 6th European Conference on Software Architecture (WICSA/ECSA), 2012, pp. 161–170. |
| [CLOUD] | Yuriy Brun and Nenad Medvidovic, Keeping Data Private while Computing in the Cloud, in Proceedings of the 5th International Conference on Cloud Computing (CLOUD), 2012, pp. 285–294. |
| [SEAMS] | Jochen Wuttke, Yuriy Brun, Alessandra Gorla, and Jonathan Ramaswamy, Traffic Routing for Evaluating Self-Adaptation, in Proceedings of the 7th International Symposium on Software Engineering for Adaptive and Self-Managing Systems (SEAMS), 2012, pp. 27–32. |
| [ICSE NIER] | Kivanç Muşlu, Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Improving IDE Recommendations by Considering Global Implications of Existing Recommendations, in Proceedings of the New Ideas and Emerging Results Track at the 34th International Conference on Software Engineering (ICSE), 2012, pp. 1349–1352. |
| [FCSD] | Yuriy Brun, Kivanç Muşlu, Reid Holmes, Michael D. Ernst, and David Notkin, Predicting Development Trajectories to Prevent Collaboration Conflicts, in the Future of Collaborative Software Development (FCSD), 2012. |
| [NatComp] | Yuriy Brun, Efficient 3-SAT algorithms in the tile assembly model, Natural Computing, vol. 11, no. 2, 2012, pp. 209–229. |
| 2011 | |
| [SIGOSP] | Ivan Beschastnikh, Yuriy Brun, Michael D. Ernst, Arvind Krishnamurthy, and Thomas E. Anderson, Mining temporal invariants from partially ordered logs, ACM SIGOPS Operating Systems Review, vol. 45, no. 3, December 2011, pp. 39–46. |
| [ASE] | George Edwards, Yuriy Brun, and Nenad Medvidovic, Isomorphism in model tools and editors, in Proceedings of the 26th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2011, pp. 458–461. |
| [SOSP WiP] | Ivan Beschastnikh, Yuriy Brun, Michael D. Ernst, Arvind Krishnamurthy, and Thomas E. Anderson, Bandsaw: Log-powered test scenario generation for distributed systems, in The Work In Progress track of the 23rd ACM Symposium on Operating Systems Principles (SOSP), 2011. |
| [ESEC/FSE Demo] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Crystal: Precise and unobtrusive conflict warnings, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering Tool Demonstration Track (ESEC/FSE), 2011, pp. 444–447. |
| [ESEC/FSE Demo] | Ivan Beschastnikh, Jenny Abrahamson, Yuriy Brun, and Michael D. Ernst, Synoptic: Studying logged behavior with inferred models, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering Tool Demonstration Track (ESEC/FSE), 2011, pp. 448–451. |
| [ESEC/FSE] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Proactive detection of collaboration conflicts, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2011, pp. 168–178 (ACM SIGSOFT Distinguished Paper Award). |
| [ESEC/FSE] | Ivan Beschastnikh, Yuriy Brun, Sigurd Schneider, Michael Sloan, and Michael D. Ernst, Leveraging existing instrumentation to automatically infer invariant-constrained models, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2011, pp. 267–277. |
| [ACL] | Chloé Kiddon and Yuriy Brun, That's what she said: Double entendre identification, in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL), 2011, pp. 89–94. |
| [ICDCS] | Yuriy Brun, George Edwards, Jae young Bang, and Nenad Medvidovic, Smart redundancy for distributed computation, in Proceedings of the 31st International Conference on Distributed Computing Systems (ICDCS), 2011, pp. 665–676. |
| [IEEE Computer] | Nenad Medvidovic, Hossein Tajalli, Joshua Garcia, Yuriy Brun, Ivo Krka, and George Edwards, Engineering heterogeneous robotics systems: A software architecture-based approach, IEEE Computer, vol. 44, no. 5, May 2011, pp. 61–71. |
| [DNA] | Yuriy Brun, Improving efficiency of 3-SAT-solving tile systems, Lecture Notes on Computer Science, vol. 6518/2011, 2011, pp. 1–12. |
| 2010 | |
| [FoSER] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Speculative analysis: Exploring future states of software, in Proceedings of the 2010 Foundations of Software Engineering Working Conference on the Future of Software Engineering Research (FoSER), pp. 59–63. |
| [SLAML] | Sigurd Schneider, Ivan Beschastnikh, Slava Chernyak, Michael D. Ernst, and Yuriy Brun, Synoptic: Summarizing system logs with refinement, in Proceedings of the Workshop on Managing Systems via Log Analysis and Machine Learning Techniques (SLAML), 2010. |
| [JSS] | Sam Malek, George Edwards, Yuriy Brun, Hossein Tajalli, Joshua Garcia, Ivo Krka, Nenad Medvidovic, Marija Mikic-Rakic, and Gaurav Sukhatme, An architecture-driven software mobility framework, Journal of Systems and Software, vol. 83, no. 6, June 2010, pp. 972–989. |
| [ICSE NIER] | Ivo Krka, Yuriy Brun, Daniel Popescu, Joshua Garcia, and Nenad Medvidovic, Using dynamic execution traces and program invariants to enhance behavioral model inference, in Proceedings of the New Ideas and Emerging Results Track at the 32nd International Conference on Software Engineering (ICSE), 2010, pp. 179–182. |
| [SEAMS] | Yuriy Brun, Improving impact of self-adaptation and self-management research through evaluation methodology, in Proceedings of Software Engineering for Adaptive and Self-Managing Systems (SEAMS), 2010, pp. 1–9. |
| 2009 | |
| [ESEC/FSE] | Ivo Krka, Yuriy Brun, George Edwards, and Nenad Medvidovic, Synthesizing partial component-level behavior models from system specifications, in Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2009, pp. 305–314. |
| [BADS] | Yuriy Brun and Nenad Medvidovic, Crystal-growth-inspired algorithms for computational grids, in Proceedings of the Workshop on Bio-Inspired Algorithms for Distributed Systems (BADS), 2009, pp. 19–26. |
| [ICSE NIER] | Ivo Krka, George Edwards, Yuriy Brun, and Nenad Medvidovic, From system specifications to component behavioral models, in Proceedings of the New Ideas and Emerging Results Track at the 31st International Conference on Software Engineering (ICSE), 2009, pp. 315–318. |
| [TCS] | Yuriy Brun and Dustin Reishus, Path finding in the tile assembly model, Theoretical Computer Science, vol. 410, no. 15, April 2009, pp. 1461–1472. |
| [Chapter] | Yuriy Brun, Giovanna Di Marzo Serugendo, Cristina Gacek, Holger Giese, Holger Kienle, Marin Litoiu, Hausi Müller, Mauro Pezzè, and Mary Shaw, Engineering self-adaptive systems through feedback loops, in Software Engineering for Self-Adaptive Systems, B. H. Cheng et al., Eds., Springer-Verlag, 2009, pp. 48–70. |
| [DNA] | Yuriy Brun and Dustin Reishus, Connecting the dots: Molecular machinery for distributed robotics, Lecture Notes on Computer Science, vol. 5347/2009, 2009, pp. 102–111. |
| [Chapter] | Betty H.C. Cheng, Rogério de Lemos, Holger Giese, Paola Inverardi, Jeff Magee, Jesper Andersson, Basil Becker, Nelly Bencomo, Yuriy Brun, Bojan Cukic, Giovanna Di Marzo Serugendo, Schahram Dustdar, Anthony Finkelstein, Cristina Gacek, Kurt Geihs, Vincenzo Grassi, Gabor Karsai, Holger M. Kienle, Jeff Kramer, Marin Litoiu, Sam Malek, Raffaela Mirandola, Hausi A. Müller, Sooyong Park, Mary Shaw, Matthias Tichy, Massimo Tivoli, Danny Weyns, and Jon Whittle, Software engineering for self-adaptive systems: A research roadmap, in Software Engineering for Self-Adaptive Systems, B. H. Cheng et al., Eds., Springer-Verlag, 2009, pp. 1–26. |
| 2008 | |
| [DNA] | Yuriy Brun, Reducing tileset size: 3-SAT and beyond, in Proceedings of the 14th International Meeting on DNA Computing (DNA), 2008, pp. 178. |
| [PhD] | Yuriy Brun, Self-assembly for discreet, fault-tolerant, and scalable computation on Internet-sized distributed networks, Ph.D. dissertation, University of Southern California, Los Angeles, CA, USA, 2008. |
| [TCS] | Yuriy Brun, Solving NP-complete problems in the tile assembly model, Theoretical Computer Science, vol. 395, no. 1, April 2008, pp. 31–46. |
| [TCS] | Yuriy Brun, Nondeterministic polynomial time factoring in the tile assembly model, Theoretical Computer Science, vol. 395, no. 1, April 2008, pp. 3–23. |
| [Dagstuhl] | Yuriy Brun, Building biologically-inspired self-adapting systems, in Proceedings of the Schloss Dagstuhl seminar 08031: Software Engineering for Self-Adaptive Systems, B. H. Cheng et al., Eds., 2008. |
| [DNA] | Yuriy Brun, Constant-size tileset for solving an NP-complete problem in nondeterministic linear time, Lecture Notes on Computer Science, vol. 4848/2008, 2008, pp. 26–35. |
| [JAlg] | Yuriy Brun, Solving satisfiability in the tile assembly model with a constant-size tileset, Journal of Algorithms, vol. 63, no. 4, 2008, pp. 151–166. |
| 2007 | |
| [EFTS] | Yuriy Brun and Nenad Medvidovic, Fault and adversary tolerance as an emergent property of distributed systems' software architectures, in Proceedings of the 2nd International Workshop on Engineering Fault Tolerant Systems (EFTS), 2007, pp. 38–43. |
| [TCS] | Yuriy Brun, Arithmetic computation in the tile assembly model: Addition and multiplication, Theoretical Computer Science, vol. 378, no. 1, June 2007, pp. 17–31. |
| [SEAMS] | Yuriy Brun and Nenad Medvidovic, An architectural style for solving computationally intensive problems on large networks, in Proceedings of Software Engineering for Adaptive and Self-Managing Systems (SEAMS), 2007 (SEAMS 2020 Most Influential Paper Award). |
| [ICSE DocSymp] | Yuriy Brun, A discreet, fault-tolerant, and scalable software architectural style for Internet-sized networks, in Proceedings of the Doctoral Symposium at the 29th International Conference on Software Engineering (ICSE), 2007, pp. 83–84. |
| [FNANO] | Yuriy Brun, Adding and multiplying in the tile assembly model, in Proceedings of the 4th Foundations of Nanoscience: Self-Assembled Architectures and Devices (FNANO), 2007. |
| 2006 | |
| [BIOCOMP] | Yuriy Brun and Manoj Gopalkrishnan, Toward in vivo disease diagnosis and treatment using DNA, in Proceedings of the 2006 International Conference on Bioinformatics & Computational Biology (BIOCOMP), pp. 182–186. |
| 2005 | |
| [JACS] | Dustin Reishus, Bilal Shaw, Yuriy Brun, Nickolas Chelyapov, and Leonard Adleman, Self-assembly of DNA double-double crossover complexes into high-density, doubly connected, planar structures, Journal of the American Chemical Society (JACS), vol. 127, no. 50, November 2005, pp. 17590–17591. |
| 2004 | |
| [JACS] | Nickolas Chelyapov, Yuriy Brun, Manoj Gopalkrishnan, Dustin Reishus, Bilal Shaw, and Leonard Adleman, DNA triangles and self-assembled hexagonal tilings, Journal of the American Chemical Society (JACS), vol. 126, no. 43, October 2004, pp. 13924–13925. |
| [ICSE] | Yuriy Brun and Michael D. Ernst, Finding latent code errors via machine learning over programs executions, in Proceedings of the 26th International Conference on Software Engineering (ICSE), 2004, pp. 480–490. |
| [FNANO] | Yuriy Brun, Manoj Gopalkrishnan, Dustin Reishus, Bilal Shaw, Nickolas Chelyapov, and Leonard Adleman, Building blocks for DNA self-assembly, in Proceedings of the 1st Foundations of Nanoscience: Self-Assembled Architectures and Devices (FNANO), 2004, pp. 2–15. |
| 2003 | |
| [M.Eng.] | Yuriy Brun, Software fault identification via dynamic analysis and machine learning, Master's thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2003. |
| 2002 | |
| [MIT UJM] | Yuriy Brun, The four-color theorem, Undergraduate Journal of Mathematics, May 2002, pp. 21–28. |
| 1997 | |
| [JSRST] | Daniel Vekhter, Alex Rasin, and Yuriy Brun, Mutual exclusion algorithms in distributed networks, Journal of Student Research, Science and Technology, vol. 2, no. 1, February 1997, pp. 65–67. |
| [TOSEM] | Yuriy Brun, Saikat Chakraborty, Claire Le Goues, Corina Păsăreanu, and Adish Singla, Automatically Engineering Trusted Software: A Research Roadmap, ACM Transactions on Software Engineering and Methodology (TOSEM), 2026. |
| [TOPLAS] | Alex Sanchez-Stern, Emily First, Timothy Zhou, Zhanna Kaufman, Yuriy Brun, and Talia Ringer, Passport: Improving Automated Formal Verification Using Identifiers, ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 45, no. 2, June 2023, pp. 12:1–12:30. |
| [TOSEM] | Yuriy Brun, Tian Lin, Jessie Elise Somerville, Elisha M. Myers, and Natalie Ebner, Blindspots in Python and Java APIs Result in Vulnerable Code, ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 32, no. 3, April 2023, pp. 76:1–76:31. |
| [EJDP] | Brittany Johnson, Jesse Bartola, Rico Angell, Sam Witty, Stephen J. Giguere, and Yuriy Brun, Fairkit, Fairkit, on the Wall, Who's the Fairest of Them All? Supporting Data Scientists in Training Fair Models, EURO Journal on Decision Processes, vol. 11, 2023. |
| [TSE] | Manish Motwani, Mauricio Soto, Yuriy Brun, and René Just, Quality of Automated Program Repair on Real-World Defects, IEEE Transactions on Software Engineering (TSE), vol. 48, no. 2, February 2022, pp. 637–661. |
| [TSE] | Afsoon Afzal, Manish Motwani, Kathryn T. Stolee, and Yuriy Brun, SOSRepair: Expressive Semantic Search for Real-World Program Repair, IEEE Transactions on Software Engineering (TSE), vol. 47, no. 10, October 2021, pp. 2162–2181. |
| [TOSEM] | Ivan Beschastnikh, Perry Liu, Albert Xing, Patty Wang, Yuriy Brun, and Michael D. Ernst, Visualizing distributed system executions, ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 29, no. 2, March 2020, pp. 9:1–9:38. |
| [Science] | Philip S. Thomas, Bruno Castro da Silva, Andrew G. Barto, Stephen Giguere, Yuriy Brun, and Emma Brunskill, Preventing Undesirable Behavior of Intelligent Machines, Science, vol. 366, no. 6468, 22 November 2019, pp. 999–1004. |
| [EMSE] | Manish Motwani, Sandhya Sankaranarayanan, René Just, and Yuriy Brun, Do Automated Program Repair Techniques Repair Hard and Important Bugs?, Empirical Software Engineering (EMSE), vol. 23, no. 5, October 2018, pp. 2901–2947. |
| [TSMC] | Seung Yeob Shin, Yuriy Brun, Hari Balasubramanian, Philip L. Henneman, and Leon J. Osterweil, Discrete-Event Simulation and Integer Linear Programming for Constraint-Aware Resource Scheduling, IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 48, no. 9, September 2018, pp. 1578–1593. |
| [CACM] | Claire Le Goues, Yuriy Brun, Sven Apel, Emery Berger, Sarfraz Khurshid, and Yannis Smaragdakis, Effectiveness of Anonymization in Double-Blind Review, Communications of the ACM, vol. 61, no. 6, June 2018, pp. 34–37. |
| [ICSE Journal First] | Manish Motwani, Sandhya Sankaranarayanan, René Just, and Yuriy Brun, Do Automated Program Repair Techniques Repair Hard and Important Bugs?, in Proceedings of the Journal First Track at the International Conference on Software Engineering (ICSE), 2018, pp. 25. |
| [IEEE Software] | Jae young Bang, Yuriy Brun, and Nenad Medvidovic, Collaborative Design Conflicts: Costs and Solutions, IEEE Software, vol. 35, no. 6, November/December 2018, pp. 25–31. |
| [CACM] | Ivan Beschastnikh, Patty Wang, Yuriy Brun, and Michael D. Ernst, Debugging Distributed Systems, Communications of the ACM, vol. 59, no. 8, August 2016, pp. 32–37. |
| [JSS] | Jie Chen, Xiwei Xu, Leon J. Osterweil, Liming Zhu, Yuriy Brun, Len Bass, Junchao Xiao, Mingshu Li, and Qing Wang, Using Simulation to Evaluate Error Detection Strategies: A Case Study of Cloud-Based Deployment Processes, Journal of Systems and Software, vol. 110, December 2015, pp. 205–221. |
| [TSE] | Claire Le Goues, Neal Holtschulte, Edward K. Smith, Yuriy Brun, Premkumar Devanbu, Stephanie Forrest, and Westley Weimer, The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 12, December 2015, pp. 1236–1256. |
| [JoNA] | Philip L. Henneman, Seung Yeob Shin, Yuriy Brun, Hari Balasubramanian, Fidela Blank, and Leon J. Osterweil, Using Computer Simulation to Study Nurse-to-Patient Ratios in an Emergency Department, The Journal of Nursing Administration, vol. 45, no. 11, November 2015, pp. 551–556. |
| [TSE] | Yuriy Brun, Jae young Bang, George Edwards, and Nenad Medvidovic, Self-Adapting Reliability in Distributed Software Systems, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 8, August 2015, pp. 764–780. |
| [TSE] | Kivanç Muşlu, Yuriy Brun, Michael D. Ernst, and David Notkin, Reducing feedback delay of software development tools via continuous analyses, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 8, August 2015, pp. 745–763. |
| [TSE] | Ivan Beschastnikh, Yuriy Brun, Jenny Abrahamson, Michael D. Ernst, and Arvind Krishnamurthy, Using declarative specification to improve the understanding, extensibility, and comparison of model-inference algorithms, IEEE Transactions on Software Engineering (TSE), vol. 41, no. 4, April 2015, pp. 408–428. |
| [TSE] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Early Detection of Collaboration Conflicts and Risks, IEEE Transactions on Software Engineering (TSE), vol. 39, no. 10, October 2013, pp. 1358–1375. |
| [TDSC] | Yuriy Brun and Nenad Medvidovic, Entrusting Private Computation and Data to Untrusted Networks, IEEE Transactions on Dependable and Secure Computing (TDSC), vol. 10, no. 4, July/August 2013, pp. 225–238. |
| [NatComp] | Yuriy Brun, Efficient 3-SAT algorithms in the tile assembly model, Natural Computing, vol. 11, no. 2, 2012, pp. 209–229. |
| [SIGOSP] | Ivan Beschastnikh, Yuriy Brun, Michael D. Ernst, Arvind Krishnamurthy, and Thomas E. Anderson, Mining temporal invariants from partially ordered logs, ACM SIGOPS Operating Systems Review, vol. 45, no. 3, December 2011, pp. 39–46. |
| [IEEE Computer] | Nenad Medvidovic, Hossein Tajalli, Joshua Garcia, Yuriy Brun, Ivo Krka, and George Edwards, Engineering heterogeneous robotics systems: A software architecture-based approach, IEEE Computer, vol. 44, no. 5, May 2011, pp. 61–71. |
| [JSS] | Sam Malek, George Edwards, Yuriy Brun, Hossein Tajalli, Joshua Garcia, Ivo Krka, Nenad Medvidovic, Marija Mikic-Rakic, and Gaurav Sukhatme, An architecture-driven software mobility framework, Journal of Systems and Software, vol. 83, no. 6, June 2010, pp. 972–989. |
| [TCS] | Yuriy Brun and Dustin Reishus, Path finding in the tile assembly model, Theoretical Computer Science, vol. 410, no. 15, April 2009, pp. 1461–1472. |
| [TCS] | Yuriy Brun, Solving NP-complete problems in the tile assembly model, Theoretical Computer Science, vol. 395, no. 1, April 2008, pp. 31–46. |
| [TCS] | Yuriy Brun, Nondeterministic polynomial time factoring in the tile assembly model, Theoretical Computer Science, vol. 395, no. 1, April 2008, pp. 3–23. |
| [JAlg] | Yuriy Brun, Solving satisfiability in the tile assembly model with a constant-size tileset, Journal of Algorithms, vol. 63, no. 4, 2008, pp. 151–166. |
| [TCS] | Yuriy Brun, Arithmetic computation in the tile assembly model: Addition and multiplication, Theoretical Computer Science, vol. 378, no. 1, June 2007, pp. 17–31. |
| [JACS] | Dustin Reishus, Bilal Shaw, Yuriy Brun, Nickolas Chelyapov, and Leonard Adleman, Self-assembly of DNA double-double crossover complexes into high-density, doubly connected, planar structures, Journal of the American Chemical Society (JACS), vol. 127, no. 50, November 2005, pp. 17590–17591. |
| [JACS] | Nickolas Chelyapov, Yuriy Brun, Manoj Gopalkrishnan, Dustin Reishus, Bilal Shaw, and Leonard Adleman, DNA triangles and self-assembled hexagonal tilings, Journal of the American Chemical Society (JACS), vol. 126, no. 43, October 2004, pp. 13924–13925. |
| [JSRST] | Daniel Vekhter, Alex Rasin, and Yuriy Brun, Mutual exclusion algorithms in distributed networks, Journal of Student Research, Science and Technology, vol. 2, no. 1, February 1997, pp. 65–67. |
| [ICML] | Kunjal Panchal, Sunav Choudhary, Yuriy Brun, and Hui Guan, Memory Savings at What Cost? A Study of Alternatives to Backpropagation, in Proceedings of the 43rd International Conference on Machine Learning (ICML), 2026. |
| [FAccT] | Aimen Gaba, Emily Wall, Os Keyes, Yuriy Brun, Kyle Wm Hall, and Cindy Xiong Bearfield, A Gender Diverse Perspective of Bias in Large Language Models, in Proceedings of the 9th ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2026, pp. 1312–1339. |
| [ICSE] | Zhanna Kaufman, Emily First, Alex Sanchez-Stern, Kyle Thompson, Sorin Lerner, and Yuriy Brun, ProofCoop: Collaborative Automated Formal Verification, in Proceedings of the 48th International Conference on Software Engineering (ICSE), 2026, pp. 1339–1352. |
| [ICSE] | Saketh Ram Kasibatla, Arpan Agrawal, Yuriy Brun, Sorin Lerner, Talia Ringer, and Emily First, Cobblestone: A Divide-and-Conquer Approach for Automating Formal Verification, in Proceedings of the 48th International Conference on Software Engineering (ICSE), 2026, pp. 714–726. |
| [TVCG] | Zhanna Kaufman, Madeline Endres, Cindy Xiong Bearfield, and Yuriy Brun, Your Model Is Unfair, Are You Even Aware? Inverse Relationship Between Comprehension and Trust in Explainability Visualizations of Biased ML Models, IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 32, no. 1, 2026, pp. 637–647. |
| [NeurIPS] | Aline Weber, Blossom Metevier, Yuriy Brun, Philip S. Thomas, and Bruno Castro da Silva, Beyond Prediction: Managing the Repercussions of Machine Learning Applications, in Proceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 38, 2025. |
| [ICSE] | Kyle Thompson, Nuno Saavedra, Pedro Carrott, Kevin Fisher, Alex Sanchez-Stern, Yuriy Brun, João F. Ferreira, Sorin Lerner, and Emily First, Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification, in Proceedings of the 47th International Conference on Software Engineering (ICSE), 2025, pp. 347–359. |
| [ICSE] | Alex Sanchez-Stern, Abhishek Varghese, Zhanna Kaufman, Dylan Zhang, Talia Ringer, and Yuriy Brun, QEDCartographer: Automating Formal Verification Using Reward-Free Reinforcement Learning, in Proceedings of the 47th International Conference on Software Engineering (ICSE), 2025, pp. 307–320. |
| [NeurIPS] | Lijun Zhang, Xiao Liu, Antoni Viros i Martin, Cindy Xiong Bearfield, Yuriy Brun, and Hui Guan, Attack-Resilient Image Watermarking Using Stable Diffusion, in Proceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 37, 2024, pp. 38480–38507. |
| [NeurIPS] | Kunjal Panchal, Nisarg Parikh, Sunav Choudhary, Lijun Zhang, Yuriy Brun, and Hui Guan, Thinking Forward: Memory-Efficient Federated Finetuning of Language Models, in Proceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 37, 2024, pp. 69069–69119. |
| [ICSE] | Hadeel Eladawy, Claire Le Goues, and Yuriy Brun, Automated Program Repair, What Is It Good For? Not Absolutely Nothing!, in Proceedings of the 46th International Conference on Software Engineering (ICSE), 2024, pp. 1017–1029. |
| [TVCG] | Aimen Gaba, Zhanna Kaufman, Jason Cheung, Marie Shvakel, Kyle Wm Hall, Yuriy Brun, and Cindy Xiong Bearfield, My Model is Unfair, Do People Even Care? Visual Design Affects Trust and Perceived Bias in Machine Learning, IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 30, no. 1, January 2024, pp. 327–337. |
| [ESEC/FSE] | Emily First, Markus Rabe, Talia Ringer, and Yuriy Brun, Baldur: Whole-Proof Generation and Repair with Large Language Models, in Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2023, pp. 1229–1241 (ACM SIGSOFT Distinguished Paper Award). |
| [ICSE SEIP] | Manish Motwani and Yuriy Brun, Understanding Why and Predicting When Developers Adhere to Code-Quality Standards, in Proceedings of the Software Engineering in Practice Track at the 45th International Conference on Software Engineering (ICSE SEIP), 2023, pp. 432–444. |
| [ICSE] | Manish Motwani and Yuriy Brun, Better Automatic Program Repair by Using Bug Reports and Tests Together, in Proceedings of the 45th International Conference on Software Engineering (ICSE), 2023, pp. 1229–1241. |
| [ESEC/FSE] | Yixue Zhao, Saghar Talebipour, Kesina Baral, Hyojae Park, Leon Yee, Safwat Ali Khan, Yuriy Brun, Nenad Medvidovic, and Kevin Moran, Avgust: Automating Usage-Based Test Generation from Videos of App Executions, in Proceedings of the 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2022, pp. 421–433. |
| [ICSE] | Emily First and Yuriy Brun, Diversity-Driven Automated Formal Verification, in Proceedings of the 44th International Conference on Software Engineering (ICSE), 2022, pp. 749–761 (ACM SIGSOFT Distinguished Paper Award). |
| [ICLR] | Stephen Giguere, Blossom Metevier, Yuriy Brun, Bruno Castro da Silva, Philip S. Thomas, and Scott Niekum, Fairness Guarantees under Demographic Shift, in Proceedings of the 10th International Conference on Learning Representations (ICLR), 2022. |
| [OOPSLA] | Emily First, Yuriy Brun, and Arjun Guha, TacTok: Semantics-Aware Proof Synthesis, Proceedings of the ACM on Programming Languages (PACMPL) Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA) issue, vol. 4, November 2020, pp. 231:1–231:31. |
| [ESEC/FSE] | Arman Shahbazian, Suhrid Karthik, Yuriy Brun, and Nenad Medvidovic, eQual: Informing Early Design Decisions, in Proceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2020, pp. 1039–1051. |
| [ICSE] | Brittany Johnson, Yuriy Brun, and Alexandra Meliou, Causal Testing: Understanding Defects' Root Causes, in Proceedings of the 42nd International Conference on Software Engineering (ICSE), 2020, pp. 87–99 (ACM SIGSOFT Distinguished Artifact Award). |
| [NeurIPS] | Blossom Metevier, Stephen Giguere, Sarah Brockman, Ari Kobren, Yuriy Brun, Emma Brunskill, and Philip S. Thomas, Offline Contextual Bandits with High Probability Fairness Guarantees, in Proceedings of the 33rd Annual Conference on Neural Information Processing Systems (NeurIPS), Advances in Neural Information Processing Systems 32, 2019, pp. 14893–14904. |
| [OOPSLA] | Abhinav Jangda, Donald Pinckney, Yuriy Brun, and Arjun Guha, Formal Foundations of Serverless Computing, Proceedings of the ACM on Programming Languages (PACMPL) Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA) issue, vol. 3, October 2019, pp. 149:1–149:26 (ACM SIGPLAN Distinguished Paper Award). |
| [ICSE] | Manish Motwani and Yuriy Brun, Automatically Generating Precise Oracles from Structured Natural Language Specifications, in Proceedings of the 41st International Conference on Software Engineering (ICSE), 2019, pp. 188–199. |
| [SOUPS] | Daniela Seabra Oliveira, Tian Lin, Muhammad Sajidur Rahman, Rad Akefirad, Donovan Ellis, Eliany Perez, Rahul Bobhate, Lois A. DeLong, Justin Cappos, Yuriy Brun, and Natalie C. Ebner, API Blindspots: Why Experienced Developers Write Vulnerable Code, in Proceedings of the USENIX Symposium on Usable Privacy and Security (SOUPS), 2018, pp. 315–328. |
| [ICSA] | Arman Shahbazian, Youn Kyu Lee, Duc Le, Yuriy Brun, and Nenad Medvidovic, Recovering Architectural Design Decisions, in Proceedings of the IEEE International Conference on Software Architecture (ICSA), 2018, pp. 95–104. |
| [ESEC/FSE] | Sainyam Galhotra, Yuriy Brun, and Alexandra Meliou, Fairness Testing: Testing Software for Discrimination, in Proceedings of the 11th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2017, pp. 498–510 (ACM SIGSOFT Distinguished Paper Award). |
| [ICSA] | Jae young Bang, Yuriy Brun, and Nenad Medvidovic, Continuous Analysis of Collaborative Design, in Proceedings of the IEEE International Conference on Software Architecture (ICSA), 2017, pp. 97–106 (Best Paper Award). |
| [ICST] | Qianqian Wang, Yuriy Brun, and Alessandro Orso, Behavioral Execution Comparison: Are Tests Representative of Field Behavior?, in Proceedings of the 10th IEEE International Conference on Software Testing, Verification, and Validation (ICST), 2017, pp. 321–332. |
| [ASE] | Aaron Weiss, Arjun Guha, and Yuriy Brun, Tortoise: Interactive System Configuration Repair, in Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), 2017, pp. 625–636. |
| [ASE] | Yalin Ke, Kathryn T. Stolee, Claire Le Goues, and Yuriy Brun, Repairing Programs with Semantic Code Search, in Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015, pp. 295–306. |
| [ISSRE] | Robert J. Walls, Yuriy Brun, Marc Liberatore, and Brian Neil Levine, Discovering Specification Violations in Networked Software Systems, in Proceedings of the 26th IEEE International Symposium on Software Reliability Engineering (ISSRE), 2015, pp. 496–506. |
| [ISSRE] | Jeff Rasley, Eleni Gessiou, Tony Ohmann, Yuriy Brun, Shriram Krishnamurthi, and Justin Cappos, Detecting Latent Cross-Platform API Violations, in Proceedings of the 26th IEEE International Symposium on Software Reliability Engineering (ISSRE), 2015, pp. 484–495. |
| [ESEC/FSE] | Edward K. Smith, Earl Barr, Claire Le Goues, and Yuriy Brun, Is the Cure Worse than the Disease? Overfitting in Automated Program Repair, in Proceedings of the 10th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2015, pp. 532–543 (FSE 2025 Test of Time Honorable Mention Award). |
| [ISSTA] | Kivanç Muşlu, Yuriy Brun, and Alexandra Meliou, Preventing Data Errors with Continuous Testing, in Proceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), 2015, pp. 373–384. |
| [FASE] | Seung Yeob Shin, Yuriy Brun, Leon J. Osterweil, Hari Balasubramanian, and Philip L. Henneman, Resource Specification for Prototyping Human-Intensive Systems, in Proceedings of the 18th International Conference on Fundamental Approaches to Software Engineering (FASE), 2015, pp. 332–346. |
| [FSE] | Earl T. Barr, Yuriy Brun, Premkumar Devanbu, Mark Harman, and Federica Sarro, The Plastic Surgery Hypothesis, in Proceedings of the 22nd ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE), 2014, pp. 306–317. |
| [FSE] | Ivo Krka, Yuriy Brun, and Nenad Medvidovic, Automatic Mining of Specifications from Invocation Traces and Method Invariants, in Proceedings of the 22nd ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE), 2014, pp. 178–189. |
| [ASE] | Tony Ohmann, Michael Herzberg, Sebastian Fiss, Armand Halbert, Marc Palyart, Ivan Beschastnikh, and Yuriy Brun, Behavioral Resource-Aware Model Inference, in Proceedings of the 29th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2014, pp. 19–30. |
| [ICSE] | Ivan Beschastnikh, Yuriy Brun, Michael D. Ernst, and Arvind Krishnamurthy, Inferring Models of Concurrent Systems from Logs of their Behavior with CSight, in Proceedings of the 36th International Conference on Software Engineering (ICSE), 2014, pp. 468–479. |
| [ESEC/FSE] | Kivanç Muşlu, Yuriy Brun, Michael D. Ernst, and David Notkin, Making Offline Analyses Continuous, in Proceedings of the 9th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2013, pp. 323–333. |
| [ICSE] | Ivan Beschastnikh, Yuriy Brun, Jenny Abrahamson, Michael D. Ernst, and Arvind Krishnamurthy, Unifying FSM-inference algorithms through declarative specification, in Proceedings of the 35th International Conference on Software Engineering (ICSE), 2013, pp. 252–261. |
| [OOPSLA] | Kivanç Muşlu, Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Speculative Analysis of Integrated Development Environment Recommendations, in Proceedings of the 27th ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA), 2012, pp. 669–682. |
| [WICSA] | George Edwards, Yuriy Brun, and Nenad Medvidovic, Automated analysis and code generation for domain-specific models, in the joint 10th Working IEEE/IFIP Conference on Software Architecture and 6th European Conference on Software Architecture (WICSA/ECSA), 2012, pp. 161–170. |
| [CLOUD] | Yuriy Brun and Nenad Medvidovic, Keeping Data Private while Computing in the Cloud, in Proceedings of the 5th International Conference on Cloud Computing (CLOUD), 2012, pp. 285–294. |
| [SEAMS] | Jochen Wuttke, Yuriy Brun, Alessandra Gorla, and Jonathan Ramaswamy, Traffic Routing for Evaluating Self-Adaptation, in Proceedings of the 7th International Symposium on Software Engineering for Adaptive and Self-Managing Systems (SEAMS), 2012, pp. 27–32. |
| [ESEC/FSE] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Proactive detection of collaboration conflicts, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2011, pp. 168–178 (ACM SIGSOFT Distinguished Paper Award). |
| [ESEC/FSE] | Ivan Beschastnikh, Yuriy Brun, Sigurd Schneider, Michael Sloan, and Michael D. Ernst, Leveraging existing instrumentation to automatically infer invariant-constrained models, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2011, pp. 267–277. |
| [ICDCS] | Yuriy Brun, George Edwards, Jae young Bang, and Nenad Medvidovic, Smart redundancy for distributed computation, in Proceedings of the 31st International Conference on Distributed Computing Systems (ICDCS), 2011, pp. 665–676. |
| [DNA] | Yuriy Brun, Improving efficiency of 3-SAT-solving tile systems, Lecture Notes on Computer Science, vol. 6518/2011, 2011, pp. 1–12. |
| [SEAMS] | Yuriy Brun, Improving impact of self-adaptation and self-management research through evaluation methodology, in Proceedings of Software Engineering for Adaptive and Self-Managing Systems (SEAMS), 2010, pp. 1–9. |
| [ESEC/FSE] | Ivo Krka, Yuriy Brun, George Edwards, and Nenad Medvidovic, Synthesizing partial component-level behavior models from system specifications, in Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2009, pp. 305–314. |
| [DNA] | Yuriy Brun and Dustin Reishus, Connecting the dots: Molecular machinery for distributed robotics, Lecture Notes on Computer Science, vol. 5347/2009, 2009, pp. 102–111. |
| [DNA] | Yuriy Brun, Constant-size tileset for solving an NP-complete problem in nondeterministic linear time, Lecture Notes on Computer Science, vol. 4848/2008, 2008, pp. 26–35. |
| [SEAMS] | Yuriy Brun and Nenad Medvidovic, An architectural style for solving computationally intensive problems on large networks, in Proceedings of Software Engineering for Adaptive and Self-Managing Systems (SEAMS), 2007 (SEAMS 2020 Most Influential Paper Award). |
| [FNANO] | Yuriy Brun, Adding and multiplying in the tile assembly model, in Proceedings of the 4th Foundations of Nanoscience: Self-Assembled Architectures and Devices (FNANO), 2007. |
| [ICSE] | Yuriy Brun and Michael D. Ernst, Finding latent code errors via machine learning over programs executions, in Proceedings of the 26th International Conference on Software Engineering (ICSE), 2004, pp. 480–490. |
| [FNANO] | Yuriy Brun, Manoj Gopalkrishnan, Dustin Reishus, Bilal Shaw, Nickolas Chelyapov, and Leonard Adleman, Building blocks for DNA self-assembly, in Proceedings of the 1st Foundations of Nanoscience: Self-Assembled Architectures and Devices (FNANO), 2004, pp. 2–15. |
| [ICSE Demo] | Austin Hoag, James E. Kostas, Bruno Castro da Silva, Philip S. Thomas, and Yuriy Brun, Seldonian Toolkit: Building Software with Safe and Fair Machine Learning, in Proceedings of the Demonstrations Track at the 45th International Conference on Software Engineering (ICSE), 2023, pp. 107–111. |
| [ICSE Demo] | Arpan Agrawal, Emily First, Zhanna Kaufman, Tom Reichel, Shizhuo Zhang, Timothy Zhou, Alex Sanchez-Stern, Talia Ringer, and Yuriy Brun, Proofster: Automated Formal Verification, in Proceedings of the Demonstrations Track at the 45th International Conference on Software Engineering (ICSE), 2023, pp. 26–30. |
| [ICSE Demo] | Saghar Talebipour, Hyojae Park, Kesina Baral, Leon Yee, Safwat Ali Khan, Kevin Moran, Yuriy Brun, Nenad Medvidovic, and Yixue Zhao, AVGUST: A Tool for Generating Usage-Based Tests from Videos of App Executions, in Proceedings of the Demonstrations Track at the 45th International Conference on Software Engineering (ICSE), 2023, pp. 83–87. |
| [ICSE Demo] | Brittany Johnson and Yuriy Brun, Fairkit-learn: A Fairness Evaluation and Comparison Toolkit, in Proceedings of the Demonstrations Track at the 44th International Conference on Software Engineering (ICSE), 2022, pp. 70–74. |
| [ESEC/FSE NIER] | Yuriy Brun and Alexandra Meliou, Software Fairness, in Proceedings of the New Ideas and Emerging Results Track at the 26th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2018, pp. 754–759. |
| [ESEC/FSE Demo] | Rico Angell, Brittany Johnson, Yuriy Brun, and Alexandra Meliou, Themis: Automatically Testing Software for Discrimination, in Proceedings of the Demonstrations Track at the 26th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2018, pp. 871–875. |
| [TSE] | Claire Le Goues, Yuriy Brun, Stephanie Forrest, and Westley Weimer, Clarifications on the Construction and Use of the ManyBugs Benchmark, IEEE Transactions on Software Engineering (TSE), comment paper, vol. 43, no. 11, November 2017, pp. 1089–1090. |
| [ICSE Demo] | Tony Ohmann, Ryan Stanley, Ivan Beschastnikh, and Yuriy Brun, Visually Reasoning about System and Resource Behavior, in Proceedings of the Demonstrations Track of the 38th International Conference on Software Engineering (ICSE Demo), 2016, pp. 601–604. |
| [ASE] | Kivanç Muşlu, Luke Swart, Yuriy Brun, and Michael D. Ernst, Simplifying Development History Information Retrieval via Multi-Grained Views, in Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015, pp. 697–702. |
| [ICSE NIER] | Tony Ohmann, Kevin Thai, Ivan Beschastnikh, and Yuriy Brun, Mining Precise Performance-Aware Behavioral Models from Existing Instrumentation, in Proceedings of the New Ideas and Emerging Results Track at the International Conference on Software Engineering (ICSE), 2014, pp. 484–487. |
| [ESEC/FSE NI] | Kivanç Muşlu, Yuriy Brun, and Alexandra Meliou, Data Debugging with Continuous Testing, in Proceedings of the New Ideas Track at the 9th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), 2013, pp. 631–634. |
| [ICSSP] | Xiang Zhao, Yuriy Brun, and Leon J. Osterweil, Supporting Process Undo and Redo in Software Engineering Decision Making, in Proceedings of the 8th International Conference on Software and System Process (ICSSP), 2013, pp. 56–60. |
| [ICSE NIER] | Roykrong Sukkerd, Ivan Beschastnikh, Jochen Wuttke, Sai Zhang, and Yuriy Brun, Understanding Regression Failures through Test-Passing and Test-Failing Code Changes, in Proceedings of the New Ideas and Emerging Results Track at the 35th International Conference on Software Engineering (ICSE), 2013, pp. 1177–1180. |
| [ICSE NIER] | Kivanç Muşlu, Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Improving IDE Recommendations by Considering Global Implications of Existing Recommendations, in Proceedings of the New Ideas and Emerging Results Track at the 34th International Conference on Software Engineering (ICSE), 2012, pp. 1349–1352. |
| [ASE] | George Edwards, Yuriy Brun, and Nenad Medvidovic, Isomorphism in model tools and editors, in Proceedings of the 26th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2011, pp. 458–461. |
| [SOSP WiP] | Ivan Beschastnikh, Yuriy Brun, Michael D. Ernst, Arvind Krishnamurthy, and Thomas E. Anderson, Bandsaw: Log-powered test scenario generation for distributed systems, in The Work In Progress track of the 23rd ACM Symposium on Operating Systems Principles (SOSP), 2011. |
| [ESEC/FSE Demo] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Crystal: Precise and unobtrusive conflict warnings, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering Tool Demonstration Track (ESEC/FSE), 2011, pp. 444–447. |
| [ESEC/FSE Demo] | Ivan Beschastnikh, Jenny Abrahamson, Yuriy Brun, and Michael D. Ernst, Synoptic: Studying logged behavior with inferred models, in Proceedings of the 8th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering Tool Demonstration Track (ESEC/FSE), 2011, pp. 448–451. |
| [ACL] | Chloé Kiddon and Yuriy Brun, That's what she said: Double entendre identification, in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL), 2011, pp. 89–94. |
| [ICSE NIER] | Ivo Krka, Yuriy Brun, Daniel Popescu, Joshua Garcia, and Nenad Medvidovic, Using dynamic execution traces and program invariants to enhance behavioral model inference, in Proceedings of the New Ideas and Emerging Results Track at the 32nd International Conference on Software Engineering (ICSE), 2010, pp. 179–182. |
| [ICSE NIER] | Ivo Krka, George Edwards, Yuriy Brun, and Nenad Medvidovic, From system specifications to component behavioral models, in Proceedings of the New Ideas and Emerging Results Track at the 31st International Conference on Software Engineering (ICSE), 2009, pp. 315–318. |
| [Chapter] | Rogério de Lemos, David Garlan, Carlo Ghezzi, Holger Giese, Jesper Andersson, Marin Litoiu, Bradley Schmerl, Danny Weyns, Luciano Baresi, Nelly Bencomo, Yuriy Brun, Javier Camara, Radu Calinescu, Myra B. Cohen, Alessandra Gorla, Vincenzo Grassi, Lars Grunske, Paola Inverardi, Jean-Marc Jezequel, Sam Malek, Raffaela Mirandola, Marco Mori, Hausi A. Müller, Romain Rouvoy, Cecilia M. F. Rubira, Eric Rutten, Mary Shaw, Giordano Tamburrelli, Gabriel Tamura, Norha M. Villegas, Thomas Vogel, and Franco Zambonelli, Software Engineering for Self-Adaptive Systems: Research Challenges in the Provision of Assurances, in Software Engineering for Self-Adaptive Systems III, R. d. Lemos et al., Eds., Springer, 2018, pp. 3–30. |
| [Chapter] | Bradley Schmerl, Jesper Andersson, Thomas Vogel, Myra B. Cohen, Cecilia M. F. Rubira, Yuriy Brun, Alessandra Gorla, Franco Zambonelli, and Luciano Baresi, Challenges in Composing and Decomposing Assurances for Self-Adaptive Systems, in Software Engineering for Self-Adaptive Systems III. Assurances, R. d. Lemos et al., Eds., Springer, 2018, pp. 64–89. |
| [Chapter] | Yuriy Brun, Ron Desmarais, Kurt Geihs, Marin Litoiu, Antonia Lopes, Mary Shaw, and Mike Smit, A design space for adaptive systems, in Software Engineering for Self-Adaptive Systems II, R. d. Lemos et al., Eds., Springer-Verlag, 2013, pp. 33–50. |
| [Chapter] | Rogério de Lemos, Holger Giese, Hausi A. Müller, Mary Shaw, Jesper Andersson, Luciano Baresi, Basil Becker, Nelly Bencomo, Yuriy Brun, Bojan Cukic, Ron Desmarais, Schahram Dustdar, Gregor Engels, Kurt Geihs, Karl M. Goeschka, Alessandra Gorla, Vincenzo Grassi, Paola Inverardi, Gabor Karsai, Jeff Kramer, Marin Litoiu, Antonia Lopes, Jeff Magee, Sam Malek, Serge Mankovskii, Raffaela Mirandola, John Mylopoulos, Oscar Nierstrasz, Mauro Pezzè, Christian Prehofer, Wilhelm Schäfer, Rick Schlichting, Bradley Schmerl, Dennis B. Smith, João P. Sousa, Gabriel Tamura, Ladan Tahvildari, Norha M. Villegas, Thomas Vogel, Danny Weyns, Kenny Wong, and Jochen Wuttke, Software engineering for self-adaptive systems: A second research roadmap, in Software Engineering for Self-Adaptive Systems II, R. d. Lemos et al., Eds., Springer-Verlag, 2013, pp. 1–32. |
| [Chapter] | Yuriy Brun, Giovanna Di Marzo Serugendo, Cristina Gacek, Holger Giese, Holger Kienle, Marin Litoiu, Hausi Müller, Mauro Pezzè, and Mary Shaw, Engineering self-adaptive systems through feedback loops, in Software Engineering for Self-Adaptive Systems, B. H. Cheng et al., Eds., Springer-Verlag, 2009, pp. 48–70. |
| [Chapter] | Betty H.C. Cheng, Rogério de Lemos, Holger Giese, Paola Inverardi, Jeff Magee, Jesper Andersson, Basil Becker, Nelly Bencomo, Yuriy Brun, Bojan Cukic, Giovanna Di Marzo Serugendo, Schahram Dustdar, Anthony Finkelstein, Cristina Gacek, Kurt Geihs, Vincenzo Grassi, Gabor Karsai, Holger M. Kienle, Jeff Kramer, Marin Litoiu, Sam Malek, Raffaela Mirandola, Hausi A. Müller, Sooyong Park, Mary Shaw, Matthias Tichy, Massimo Tivoli, Danny Weyns, and Jon Whittle, Software engineering for self-adaptive systems: A research roadmap, in Software Engineering for Self-Adaptive Systems, B. H. Cheng et al., Eds., Springer-Verlag, 2009, pp. 1–26. |
| [DLS] | Donald Pinckney, Arjun Guha, and Yuriy Brun, Wasm/k: Delimited Continuations for WebAssembly, in Proceedings of the ACM SIGPLAN International Symposium on Dynamic Languages (DLS), 2020, pp. 16–28. |
| [SEHS] | Seung Yeob Shin, Yuriy Brun, and Leon J. Osterweil, Specification and Analysis of Human-Intensive System Resource-Utilization Policies, in Proceedings of the 8th International Workshop on Software Engineering in Healthcare Systems (SEHS), 2016, pp. 8–14. |
| [SEHC] | Seung Yeob Shin, Hari Balasubramanian, Yuriy Brun, Philip L. Henneman, and Leon J. Osterweil, Resource Scheduling through Resource-Aware Simulation of Emergency Departments, in Proceedings of the 5th International Workshop on Software Engineering in Health Care (SEHC), 2013, pp. 64–70. |
| [TaPP] | Xiang Zhao, Emery R. Boose, Yuriy Brun, Barbara Staudt Lerner, and Leon J. Osterweil, Supporting Undo and Redo in Scientific Data Analysis, in Proceedings of the 5th USENIX Workshop on the Theory and Practice of Provenance (TaPP), 2013. |
| [FCSD] | Yuriy Brun, Kivanç Muşlu, Reid Holmes, Michael D. Ernst, and David Notkin, Predicting Development Trajectories to Prevent Collaboration Conflicts, in the Future of Collaborative Software Development (FCSD), 2012. |
| [FoSER] | Yuriy Brun, Reid Holmes, Michael D. Ernst, and David Notkin, Speculative analysis: Exploring future states of software, in Proceedings of the 2010 Foundations of Software Engineering Working Conference on the Future of Software Engineering Research (FoSER), pp. 59–63. |
| [SLAML] | Sigurd Schneider, Ivan Beschastnikh, Slava Chernyak, Michael D. Ernst, and Yuriy Brun, Synoptic: Summarizing system logs with refinement, in Proceedings of the Workshop on Managing Systems via Log Analysis and Machine Learning Techniques (SLAML), 2010. |
| [BADS] | Yuriy Brun and Nenad Medvidovic, Crystal-growth-inspired algorithms for computational grids, in Proceedings of the Workshop on Bio-Inspired Algorithms for Distributed Systems (BADS), 2009, pp. 19–26. |
| [DNA] | Yuriy Brun, Reducing tileset size: 3-SAT and beyond, in Proceedings of the 14th International Meeting on DNA Computing (DNA), 2008, pp. 178. |
| [EFTS] | Yuriy Brun and Nenad Medvidovic, Fault and adversary tolerance as an emergent property of distributed systems' software architectures, in Proceedings of the 2nd International Workshop on Engineering Fault Tolerant Systems (EFTS), 2007, pp. 38–43. |
| [ICSE DocSymp] | Yuriy Brun, A discreet, fault-tolerant, and scalable software architectural style for Internet-sized networks, in Proceedings of the Doctoral Symposium at the 29th International Conference on Software Engineering (ICSE), 2007, pp. 83–84. |
| [BIOCOMP] | Yuriy Brun and Manoj Gopalkrishnan, Toward in vivo disease diagnosis and treatment using DNA, in Proceedings of the 2006 International Conference on Bioinformatics & Computational Biology (BIOCOMP), pp. 182–186. |
| [ICSE Journal First] | Manish Motwani, Sandhya Sankaranarayanan, René Just, and Yuriy Brun, Do Automated Program Repair Techniques Repair Hard and Important Bugs?, in Proceedings of the Journal First Track at the International Conference on Software Engineering (ICSE), 2018, pp. 25. |
| [ICSE Poster] | Arman Shahbazian, Youn Kyu Lee, Yuriy Brun, and Nenad Medvidovic, Poster: Making Well-Informed Software Design Decisions, in Proceedings of the Poster Track at the International Conference on Software Engineering (ICSE), 2018, pp. 262–263. |
| [ICSE Poster] | Jenny Abrahamson, Ivan Beschastnikh, Yuriy Brun, and Michael D. Ernst, Shedding Light on Distributed System Executions, in Proceedings of the Poster Track at the International Conference on Software Engineering (ICSE), 2014, pp. 598–599. |
| [TinyToCS] | Jochen Wuttke, Ivan Beschastnikh, and Yuriy Brun, Effects of Centralized and Distributed Version Control on Commit Granularity, Tiny Transactions on Computer Science, vol. 1, September 2012. |
| [FairWare] | Y. Brun, B. Johnson, A. Meliou, Eds., Proceedings of the IEEE/ACM International Workshop on Software Fairness (FairWare), 2018. |
| [MaLTeSQuE Keynote] | Yuriy Brun, The Promise and Perils of Using Machine Learning When Engineering Software (Keynote Paper), in Proceedings of the International Workshop on Machine Learning Techniques for Software Quality Evaluation (MaLTeSQuE), 2022, pp. 1–4. |
| [FairWare] | Yuriy Brun, Brittany Johnson, and Alexandra Meliou, Message from the FairWare 2018 Chairs, in Proceedings of the IEEE/ACM International Workshop on Software Fairness, 2018. |
| [PhD] | Yuriy Brun, Self-assembly for discreet, fault-tolerant, and scalable computation on Internet-sized distributed networks, Ph.D. dissertation, University of Southern California, Los Angeles, CA, USA, 2008. |
| [Dagstuhl] | Yuriy Brun, Building biologically-inspired self-adapting systems, in Proceedings of the Schloss Dagstuhl seminar 08031: Software Engineering for Self-Adaptive Systems, B. H. Cheng et al., Eds., 2008. |
| [M.Eng.] | Yuriy Brun, Software fault identification via dynamic analysis and machine learning, Master's thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2003. |
| [MIT UJM] | Yuriy Brun, The four-color theorem, Undergraduate Journal of Mathematics, May 2002, pp. 21–28. |
Current PhD students (advisor):
|
|
|
|
|
|
|
|
|
|







Current Masters and undergraduate students:
- Marie Shvakel (masters)
Alumni postdocs:
|
|
|
|



Alumni PhD students (advisor):
|
|
|
|
|
|
|





Alumni PhD students (committee member):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|





 Pinar Ozisik
Pinar Ozisik Qianqian Wang
Qianqian Wang John Vilk
John Vilk





Alumni Masters and undergraduate students:
- Marie Shvakel received her BS degree in 2025 UMass.
- Morgan Waterman (undergraduate) received their BS degree in 2025 UMass.
- Simran Lekhwani received her BS degree in 2025 UMass.
- Declan Gray-Mullen received his Masters degree in 2022 and his BS degree in 2021 from UMass.
- Sarah Brockman received her Masters degree in 2021 and received her BS degree with honors in 2019 from UMass, currently an R&D Engineer at Kitware.
- Jennifer Halbleib received her Masters degree in 2020 from UMass, currently a Senior Data Scientist at Amazon Web Services.
- Donald Pinckney received his Masters degree in 2020 from UMass, currently getting his PhD at Northeastern University.
- Rico Angell received his Masters degree in 2019 and BS degree with honors in 2016 from UMass, currently getting his PhD at UMass.
- Tanya Asnani received her BS degree with honors in 2019 from UMass, currently at Bank of America Merrill Lynch.
- Jesse Bartola received his BS degree in 2019 from UMass, currently a senior software engineer at Hubspot.
- Aisiri Murulidhar received her BS degree in 2019 from UMass, currently a software engineer at Google, Inc.
- Natcha Simsiri received his Masters degree in 2018 and BS degree with honors in 2016 from UMass, currently at Lutron Electronics.
- Nicholas Perello received his BS degree with honors in 2018 from UMass, currently a PhD student at UMass.
- Ted Smith received his Masters degree in 2016 from UMass, currently at Bloomberg.
- Ryan Stanley received his BS degree with honors in 2016 from UMass, currently a software engineer at Amazon.com.
- Karthik Kannappan received a Masters degree in 2015 from UMass, now a software engineer at Juniper Networks.
- Armand Halbert received a Masters degree in 2015 from UMass, now a software engineer at IBM.
- Chris Ciollaro, received his BS degree in 2015 from UMass, currently a Masters student.
- Xiang Zhao (co-advised with Leon J. Osterweil) received a Masters degree in 2014 from UMass, now a software engineer at Google Inc.
- Nicholas Braga, honors thesis, received his BS degree in 2014 from UMass, currently a software engineer at BookBub.
- Brian Stapleton, received a BS degree in 2014 from UMass, now a software engineer at AdHarmonics Inc.
- Alice Ouyang, received a BS degree in 2013 from UW, now an IT Analyst at Liberty Mutual Insurance
- Brandon McNew (REU in summer of 2013), received a BS degree in 2013 from Hendrix College, now software developer at CUSi
- Jeanderson Barros (REU in summer of 2013)
- Roykrong Sukkerd, received a BS degree in 2013 from UW, now a PhD student at Carnegie Mellon University
- Haochen Wei, received a BS degree in 2013 from UW, now a software developer at LinkedIn
- Jonathan Ramaswamy, received a BS degree in 2012 from UW, now an associate consultant at Cirrus10
- Fall 2024: CS 320: Introduction to Software Engineering
- Fall 2024: CS 429: Software Engineering Project Management
- Fall 2024: CS 692P: Hot Topics in Software Engineering Research
- Spring 2024: CS 320: Introduction to Software Engineering
- Spring 2024: CS 429: Software Engineering Project Management
- Spring 2023: CS 621: Advanced Software Engineering: Analysis and Evaluation
- Fall 2022: CS 320: Introduction to Software Engineering
- Fall 2022: CS 429: Software Engineering Project Management
- Spring 2018: CS 692P: Hot Topics in Software Engineering Research
- Fall 2018: CS 520: Theory and Practice of Software Engineering
- Spring 2018: CS 621: Advanced Software Engineering: Analysis and Evaluation
- Spring 2018: CS 692P: Programming Languages & Systems Seminar
- Fall 2017: CS 520: Theory and Practice of Software Engineering
- Spring 2017: CS 521: Software Engineering: Analysis and Evaluation
- Spring 2017: CS 621: Advanced Software Engineering: Analysis and Evaluation
- Fall 2015: CS 521: Software Engineering: Analysis and Evaluation
- Fall 2015: CS 621: Advanced Software Engineering: Analysis and Evaluation
- Spring 2015: CS 320: Introduction to Software Engineering
- Spring 2015: CS H320: Introduction to Software Engineering Honors Colloquium
- Spring 2015: CS 529: Software Engineering Project Management
- Fall 2014: CS 521: Software Engineering: Analysis and Evaluation
- Fall 2014: CS 621: Advanced Software Engineering: Analysis and Evaluation
- Fall 2013: CS 521: Software Engineering: Analysis and Evaluation
- Fall 2013: CS 621: Advanced Software Engineering: Analysis and Evaluation
- Spring 2013: CS 320: Introduction to Software Engineering
- Spring 2013: CS H320: Introduction to Software Engineering Honors Colloquium
- Spring 2013: CS 529: Software Engineering Project Management
- Fall 2012: CS 521: Software Engineering: Analysis and Evaluation
- Fall 2012: CS 621: Advanced Software Engineering: Analysis and Evaluation
- Spring 2012: CSE590N: Software Engineering Seminar
- Winter 2012: CSE590N: Software Engineering Seminar
- Autumn 2011: CSE590N: Software Engineering Seminar
- Winter 2011: CSE403: Software Engineering
|
Involving undergraduates in research is central to my mission as faculty. I started my research career in earnest as an undergraduate and it is only due to the patience and support of my mentors that I am who I am today. I work hard to pay back the community by encouraging undergraduate students to experience research. But I don't consider this service; some of my best collaborations came from working with undergraduates. Focusing especially on groups underrepresented in our community, such as women and minorities, I have been lucky enough to work with brilliant undergraduate students, publishing top venue conference papers with them at FSE'11, ICSE'13, ASE'14, ISSRE'15, and IEEE TSE, as well as several shorter new ideas, emerging results, and demonstration papers at FSE'11 ICSE'13, ICSE'14, and ICSE'16. These students have gone on to great positions, both in industry and graduate school, pursuing their PhD degrees. For example, Roykrong Sukkerd (pictured on left at ICSE'13) is now a PhD student at Carnegie Mellon University, and Jenny Abrahamson received her Masters degree in Computer Science from the University of Washington and is currently a software engineer at Facebook Inc. Expanding my reach, through the NSF REU program, I have worked with several great students such as Brandon McNew from Hendrix College in Conway, Arkansas, USA, who would otherwise have no exposure to research. |

|
I attended public K–12 schools in Massachusetts and benefited
greatly from my education. At UMass, I am lucky to be surrounded by
opportunities to give back. I work with a local chapter of Girls Inc. to promote
science and technology to women aged 12–18 through the Eureka!
program. The women spend five weeks every summer at UMass
(returning for up to five years), working with faculty through
collaborative workshops to learn about STEM fields and have fun with
science! In the later years, students engage in one-on-one research
with faculty and get a great start on their college careers. Starting
in Fall 2015, Eureka! expanded to school-year Saturday workshops
and I am proud to be a part of that expansion. Watch one video about
Eureka!, and another one. |

|
My research strives to solve problems relevant to industry and the
real world. I collaborate with industry and my students often go on
internships to implement our work within companies. My work has been
supported by Microsoft (via a 2014 Microsoft Research SEIF award) and
Google (via a 2015 Google Faculty Research Award). |
|
Central to science, and to scientific careers, is the peer-review process. Unfortunately, research has shown overwhelming evidence that certain subconscious biases adversely affect the fairness of peer-review, most often hurting women and minorities. Fortunately, double-blind peer-review has been shown to successfully mitigate these negative affects. Regrettably, my research community, the Software Engineering research community, has been slow to employ double-blind reviewing at its top venues. Given the weight publications at these venues have in hiring and promotion decisions, I could not idly stand by. In late 2014, I began a campaign to convince the organizers of ICSE, the top conference in our field, to use double-blind review. In April 2015, I wrote an open letter to the community, laying out the research supporting the existence of bias in single-blind reviewing, and the benefits and potential costs of double-blind reviewing. ICSE took the proposal and evidence seriously, and I am currently serving on the ICSE Double Blind Review Task Force to concretely identify the needs, costs, and benefits of the process, as it applies directly to ICSE. ICSE 2018 will use the double blind-review process! Thanks to the hard work of my colleagues, several other Software Engineering conferences, including ASE, ISSTA, and FASE, have announced that they also will begin using double-blind reviewing. Read more about the scientific evidence for the need for double-blind reviewing. |
|
Organizing broadly inclusive, targeted-topic workshops is one of
the most effective ways to get students involved in research and to create
the kind of powerful collaborations that occur only when people with
real-world problems meet face to face with people who create
solutions. I have co-organized two such workshops. In 2013, I
co-organized the Future of
Software Engineering symposium (pictured on right) in Redmond, WA, USA to bring
together the most prominent Software Engineering researches to discuss
key future directions for the community. With generous support from the
NSF and Microsoft Research, 40 graduate and undergraduate students came
to learn about these directions, share their ideas, and reason about how
their research contributes to the greater good. Videos of the presentations
further increase the broader impact of this workshop. |

The Erdös number describes the "collaborative distance" between a person and the mathematician Paul Erdös, as measured by the authorship of scientific papers. Currently, my Erdös number is 3.
- Yuriy Brun coauthored with Leonard
M. Adleman:
DNA Triangles and Self-Assembled Hexagonal Tilings in the Journal of the American Chemical Society - Leonard M. Adleman coauthored with Andrew M.
Odlyzko:
Irreducibility testing and factorization of polynomials in the 1981 Symposium on the Foundations of Computer Science - Andrew M. Odlyzko coauthored with Paul
Erdös:
On the density of odd integers of the form (p − 1)2−n and related questions in the Journal of Number Theory
The world of academia is one of the last professions that follows the master-apprentice relationship to indoctrinate new members. In order to become a doctor of philosophy, a crucial step in the quest to become a professor and a researcher, each student is closely and personally advised by his or her mentor. That mentor, often referred to as one's academic "father" or "mother," is responsible for shaping young minds into those of diligent, honest, and ethical scientists. Below is the genealogy of my upbringing, in chronological order, tracing back to the mid 17th century, and including the founders of calculus, basic mathematical theory, and computer science.
- Erhard Weigel (who received his Ph.D. in 1650) spent much of his life popularizing science to make it more accessible to the public, and now has the Weigel crater on the moon named after him.
- His student, Gottfried Wilhelm Leibniz (1666), invented calculus, discovered the binary system and the foundation of virtually all modern computer architectures.
- Gottfried's student, Jacob Bernoulli (1684), was the first to develop the technique for solving separable differential equations and introduced the law of large numbers.
- His brother and student, Johann Bernoulli (1694), supported Descartes' vortex theory over Newton's theory of gravitation, which ultimately delayed acceptance of Newton's theory in Europe. Perhaps in a display of karma, Johann lost the naming rights to the L'Hôpital's rule, despite inventing it.
- While young, Johann educated Leonhard Euler (1726), the preeminent mathematician of the 18th century, who introduced much of modern terminology and notation to mathematics, particularly analysis, including the notion of a mathematical function. He has been featured on Swiss bank notes and numerous postage stamps has had asteroid named after him.
- Euler advised Joseph Louis Lagrange, who is most famous for inventing the Lagrange multipliers for finding the extrema of functions taking into account possible constraints.
- One of his three students, Simeon Denis Poisson (1802) is best known for the Poisson's equation, a generalization of Laplace's equation, and also for the Poisson distribution.
- Simeon taught Michel Chasles (1814), who established several important theorems (all called Chasles' theorems), one of which, on solid body kinematics, was seminal for understanding solid bodies' motions and to the development of the theories of dynamics of rigid bodies.
- Michel's student, Hubert Anson Newton (1850), was a worldwide authority on the subjects of meteors and comets, and educated Eliakim Hastings Moore.
- Eliakim Hastings Moore (1885) proved that every finite field is a Galois field, reformulated Hilbert's axioms for geometry so that points were the only primitive notion, and showed that one of Hilbert's axioms for geometry was redundant.
- One of Eliakim's students, Oswald Veblen (1903), was involved with the project that produced the pioneering ENIAC electronic digital computer.
- His student, Alonzo Church (1927), was the author of λ-calculus and the hypothesis, known as Church's Thesis, that every effectively calculable function (effectively decidable predicate) is general recursive. Together with Turing's thesis, Church's thesis forms the foundation of computer science as we know it.
- His student, John Barkley Rosser (1934), showed that the original λ-calculus was inconsistent.
- John's student, Gerald Enoch Sacks (1961), and, in turn, his student, James Claggett Owings, Jr. (1966), worked on recursion theory.
- James' student, Leon J. Osterweil (1971), works in the field of software engineering, concentrating on specification and analysis of the processes that guide software development.
- Leon's student, Richard N. Taylor (1980), founded the Department of Informatics at the University of California Irvine, is the director of the Institute for Software Research, and works on software design and architectures, especially event-based and peer-to-peer systems.
- Richard's student, and my advisor, Nenad Medvidović (1999), is the director of the USC Center for Systems and Software Engineering and his work focuses on architecture-based software development.
- I, Yuriy Brun (2008), one of Nenad's students, am working on easing the process of developing software by automating certain aspects of ensuring robustness, security, and scalability in software systems.