Causality in Databases
Explaining Query Answers with Causal Relationships
 When analyzing data sets, users are often interested in the causes of their
observations: "What caused my personalized newsfeed to contain more than 10 items related to volcanos?", "Why
can't I find any flights with my search criteria?". Database research
that addresses these or similar questions is mainly work on lineage of
query results, such as why or where provenance, and very recently,
explanations for non-answers. While these approaches differ over what
the response to questions should be, all of them seem to be linked
through a common underlying theme: understanding causal
relationships in databases.
When analyzing data sets, users are often interested in the causes of their
observations: "What caused my personalized newsfeed to contain more than 10 items related to volcanos?", "Why
can't I find any flights with my search criteria?". Database research
that addresses these or similar questions is mainly work on lineage of
query results, such as why or where provenance, and very recently,
explanations for non-answers. While these approaches differ over what
the response to questions should be, all of them seem to be linked
through a common underlying theme: understanding causal
relationships in databases.
Causal relationships cannot be explicitly modeled in current database systems, which offer no specific support for such queries. Mining techniques can infer statistically significant data patterns but they are not sufficient to draw conclusions, as correlation does not necessarily imply causation. The goal of this project is to extend the capabilities of current database systems by incorporating to them causal reasoning. This will allow databases to model causal dependencies, and users to issue queries that can interpret them to provide explanations for their observations. Starting from the very basic functionality of justifying the presence or absence of results for a given query, causality-enabled databases can find many practical applications. For an intuitive introduction and several motivating examples see the Data Bulletin article [5].

Applications in error diagnosis and cleaning
Data transformations from a source to a target dataset are ubiquitous today and can be found in data integration, data exchange, and ETL tools. Users often detect errors in the target data. For example, a user may detect that an item in a target data instance is incorrect: the tuple should not be there, or some of its attribute values are erroneous; she would like to find out which of the many input tuples that contributed to the incorrect output is faulty. It is critical that the error be traced and corrected in the source data, because once an error is identified, one can prevent it from propagating to multiple items in the target data. This can be viewed as a form of "post-factum" data cleaning: while in standard data cleaning one corrects errors before the data is transformed and integrated, in our setting the errors are detected only after the data has been transformed.
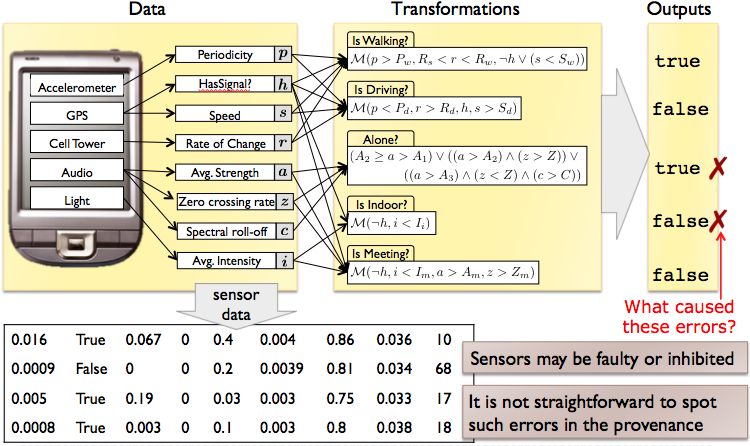
Example (Recommendation System): Consider a new generation smart phone. It has multiple sensors (e.g. GPS, accelerometer, light, and cell tower signal). Based on these sensors, a set of classifiers can predict the owner's current activities (e.g. walking, driving, working, being with family, or being in a business meeting). Using the knowledge of the user's current activities allows the system to serve the user with useful targeted recommendations. For example, if the user is away from their car around lunch time, the application will suggest restaurants within walking distance.
This is an example of data transformation: the source data (input) are the sensors, the target data (output) are the activities. Inaccuracies in the sensor data are a common occurrence: sensors have innate imprecisions (e.g., the GPS may miscalculate the current location), or some sensors may become inhibited (e.g., if the user places the cellphone in the glove compartment while driving, then the light sensor's reading is incorrect). As a consequence, an inferred activity may be wrong. The application can often detect such errors from user feedback or based on the user's subsequent actions and reactions to the provided recommendations. But the main challenge is to actually identify the responsible sensor(s). With this knowledge, the system could inhibit the reading from that sensor and therefore improve the other classifiers.
Publications
Cibele Freire, Wolfgang Gatterbauer, Neil Immerman, and Alexandra Meliou
PVLDB 9(3): 180-191 (2015). (appears at VLDB 2016)
[
 Paper ]
[ Full version]
Paper ]
[ Full version]
Causality and Explanations in Databases (Tutorial)
Alexandra Meliou, Sudeepa Roy, and Dan Suciu.
PVLDB 2014.
[
Paper][ bib]
[
bib]
[ Slides]
Slides]
Tracing Data Errors with View-Conditioned Causality
Alexandra Meliou, Wolfgang Gatterbauer, Suman Nath, and Dan Suciu.
SIGMOD 2011.
[
Paper][ bib]
[ Slides]
[Slides]
Slides]
[Slides]
Bring Provenance to its Full Potential Using Causal Reasoning
Alexandra Meliou, Wolfgang Gatterbauer, and Dan Suciu.
TaPP 2011
[
Paper]Default-all is dangerous
Wolfgang Gatterbauer, Alexandra Meliou, Dan Suciu
TaPP 2011
[
Paper],
[ Illustration Slides],
[ Illustration Slides] The Complexity of Causality and Responsibility for Query Answers and non-Answers
Alexandra Meliou, Wolfgang Gatterbauer, Katherine F. Moore, and Dan Suciu.
PVLDB 4(1): 34-45 (2010). (appears at VLDB 2011)
[
Paper ][ bib]
[Slides]
Full 15 page version with all proofs: [
arXiv:1009.2021] [ bib](Version Sept 2010)Causality in Databases
Alexandra Meliou, Wolfgang Gatterbauer, Joseph Halpern, Christoph Koch, Katherine F. Moore,
and Dan Suciu.
IEEE Data Engineering Bulletin, Special issue on Data Provenance, 33(3):59-67, Sept. 2010.
[
Paper][ bib]Why so? or Why no? Functional Causality for Explaining Query Answers
Alexandra Meliou, Wolfgang Gatterbauer, Katherine F. Moore, and Dan Suciu.
MUD 2010, pp. 3-17.
[
Paper]Full 18 page version with all proofs: [
UW CSE TR 09-12-01 (arXiv:0912.5340)] [ bib] (Dec 2009)Contributors
| Wellesley College | |
| Northeastern University | |
| University of Massachusetts, Amherst | |
| University of Massachusetts, Amherst | |
| University of Washington |
Collaborations and Funding
This project has been funded in part by NSF grants IIS-0911036 and IIS-1453543. Any opinions, findings, and conclusions or recommendations expressed in this project are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.