**A Bayesian Perspective on the Deep Image Prior**
[Zezhou Cheng](http://people.cs.umass.edu/~zezhoucheng), [Matheus Gadelha](http://mgadelha.me), [Subhransu Maji](http://people.cs.umass.edu/~smaji/), [Daniel Sheldon](https://people.cs.umass.edu/~sheldon/)
_University of Massachusetts - Amherst_
The [deep image prior](https://dmitryulyanov.github.io/deep_image_prior) was recently introduced as a prior for natural images. It represents images as the output of a convolutional network with random inputs. For “inference”, gradient descent is performed to adjust network parameters to make the output match observations. This approach yields good performance on a range of image reconstruction tasks. We show that the deep image prior is asymptotically equivalent to a stationary Gaussian process prior in the limit as the number of channels in each layer of the network goes to infinity, and derive the corresponding kernel. This informs a Bayesian approach to inference. We show that by conducting posterior inference using stochastic gradient Langevin we avoid the need for early stopping, which is a drawback of the current approach, and improve results for denoising and impainting tasks. We illustrate these intuitions on a number of 1D and 2D signal reconstruction tasks.
Publication
==========================================================================================
**A Bayesian Perspective on the Deep Image Prior**
Zezhou Cheng, Matheus Gadelha, Subhransu Maji, Daniel Sheldon
Computer Vision and Pattern Recognition (CVPR), 2019
[arXiv](https://arxiv.org/abs/1904.07457), [pdf](./gp-dip.pdf), [supplementary](./gp-dip-supp.pdf), [poster](./gp-dip-poster.pdf), [bibtex](./gp-dip.bib)
Code
==========================================================================================
[GitHub Link](https://github.com/ZezhouCheng/GP-DIP)
Main Discovery
==========================================================================================
**1. Deep Image Prior (DIP) is asymptotically equivalent to a stationary Gaussian Process (GP) prior**
* **We derive the analytical form of the GP kernel and analyze the effect of convolution, upsampling, downsampling and skip connections in the resulting GP kernel.**
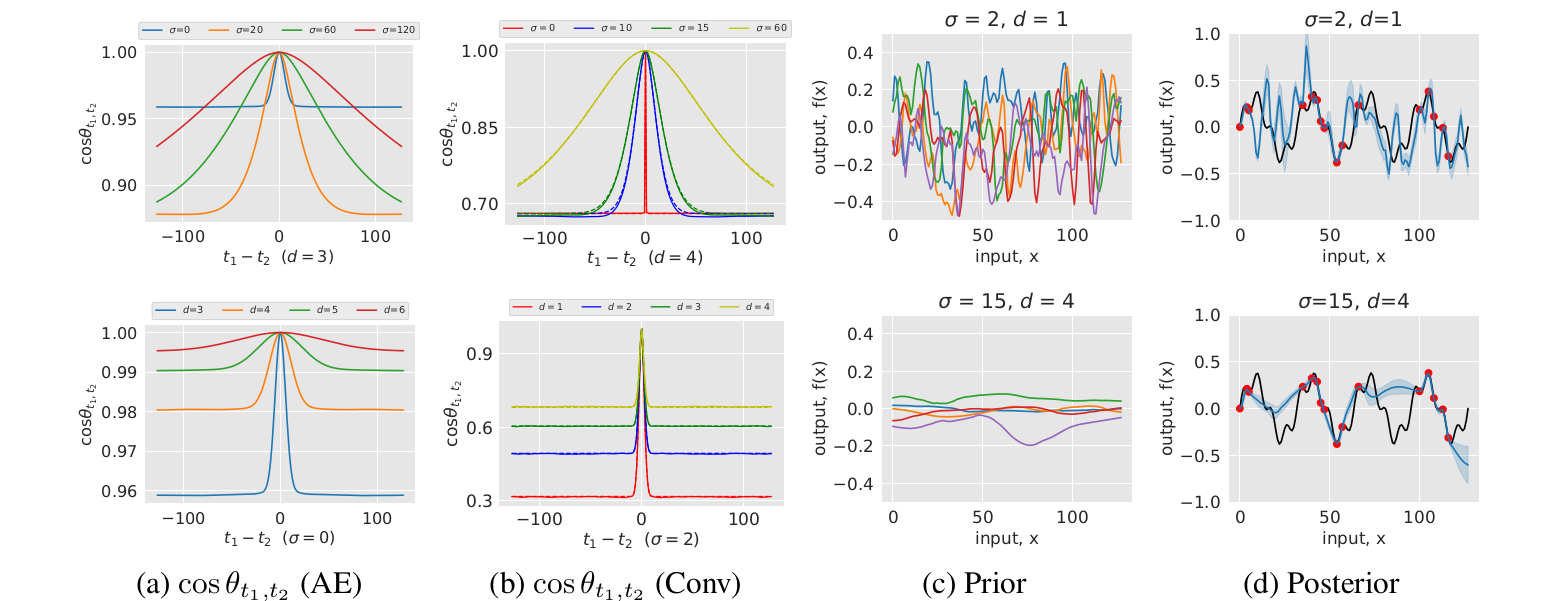
* **The samples drawn from the DIP and GP prior with equivalent stationary kernel are shown below.**
 * **The posterior mean estimated by the SGD with the DIP matches the GP posterior mean as the number of channels in the network increases. However posterior inference with long-tail GP kernels is slow for large images compared to SGD inference of the DIP.**

**2. SGLD: a Bayesian inference method for deep image prior**
* **Inference with SGD requires early stopping since the MSE with respect to the input eventually goes to zero, thus overfitting to the noise. SGLD on the other hand doesn't and samples from the posterior provide a notion of uncertainty.**
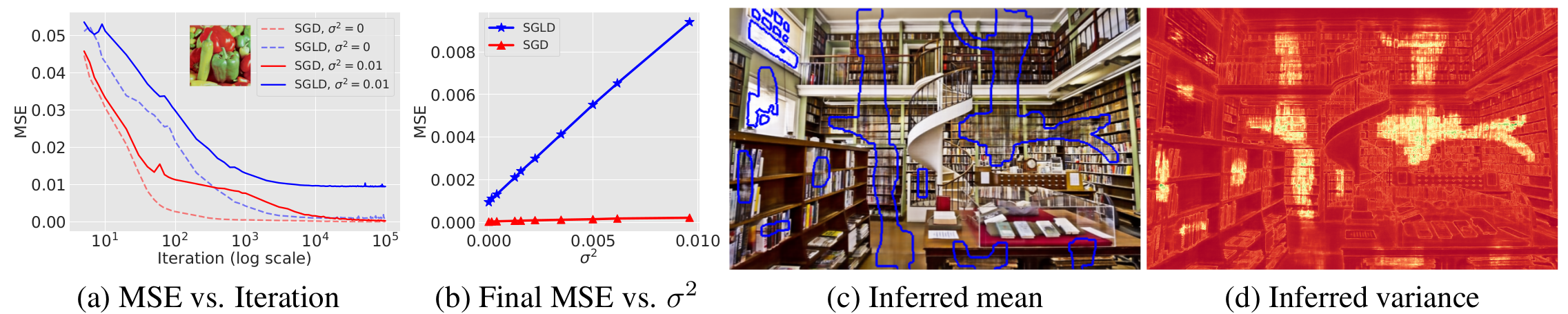
* **SGLD performs better than vanilla gradient descent on image denoising and inpainting tasks. The PSNR for various images are shown below. See paper for details.**
* **The posterior mean estimated by the SGD with the DIP matches the GP posterior mean as the number of channels in the network increases. However posterior inference with long-tail GP kernels is slow for large images compared to SGD inference of the DIP.**

**2. SGLD: a Bayesian inference method for deep image prior**
* **Inference with SGD requires early stopping since the MSE with respect to the input eventually goes to zero, thus overfitting to the noise. SGLD on the other hand doesn't and samples from the posterior provide a notion of uncertainty.**

* **SGLD performs better than vanilla gradient descent on image denoising and inpainting tasks. The PSNR for various images are shown below. See paper for details.**


 Input SGD SGLD
| | House | Peppers | Lena | Baboon | F16 | Kodak1 | Kodak2 | Kodak3 | Kodak12 | Avg. |
|:------:|:-------:|:---------:|:-------:|:--------:|:-------:|:--------:|:--------:|:--------:|:---------:|:---------:|
| SGD | 26.74 | 28.42 | 29.17 | 23.50 | 29.76 | 26.61 | 28.68 | 30.07 | 29.78 | 28.08 |
| SGLD | **30.86** | **30.82** | **32.05** | **24.54** | **32.90** | **27.96** | **32.05** | **33.29** | **32.79** | **30.81** |
[Image denoising task]
Input SGD SGLD
| | House | Peppers | Lena | Baboon | F16 | Kodak1 | Kodak2 | Kodak3 | Kodak12 | Avg. |
|:------:|:-------:|:---------:|:-------:|:--------:|:-------:|:--------:|:--------:|:--------:|:---------:|:---------:|
| SGD | 26.74 | 28.42 | 29.17 | 23.50 | 29.76 | 26.61 | 28.68 | 30.07 | 29.78 | 28.08 |
| SGLD | **30.86** | **30.82** | **32.05** | **24.54** | **32.90** | **27.96** | **32.05** | **33.29** | **32.79** | **30.81** |
[Image denoising task]

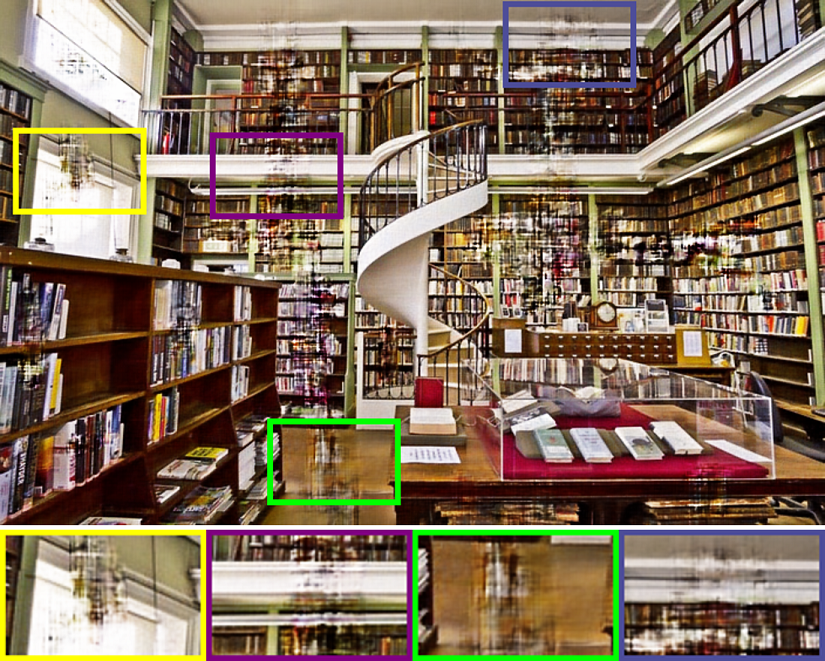
 Input SGD (19.23 dB) SGLD (21.86 dB)
| | Barb. | Boat | House | Lena | Peppers | C.man | Couple | Finger | Hill | Man | Mont. | Avg. |
|:----:|:-------:|:-----:|:-----:|:-----:|:-------:|:-----:|:------:|:------:|:-----:|:-----:|:-------:|:-------:|
| SGD | 28.48 | 31.54 | 35.34 | 35.00 | 30.40 | 27.05 | 30.55 | 32.24 | 31.37 | 31.32 | 30.21 | 28.08 |
| SGLD | **33.82** | **34.26** | **40.13** | **37.73** | **33.97** | **30.33** | **33.72** | **33.41** | **34.03** | **33.54** | **34.65** | **34.51** |
[Image inpainting task]
Acknowledgements
==========================================================================================
Thiss research was supported in part by NSF grants #1749833, #1749854, and #1661259, and the MassTech Collaborative for funding the UMass GPU cluster.
Input SGD (19.23 dB) SGLD (21.86 dB)
| | Barb. | Boat | House | Lena | Peppers | C.man | Couple | Finger | Hill | Man | Mont. | Avg. |
|:----:|:-------:|:-----:|:-----:|:-----:|:-------:|:-----:|:------:|:------:|:-----:|:-----:|:-------:|:-------:|
| SGD | 28.48 | 31.54 | 35.34 | 35.00 | 30.40 | 27.05 | 30.55 | 32.24 | 31.37 | 31.32 | 30.21 | 28.08 |
| SGLD | **33.82** | **34.26** | **40.13** | **37.73** | **33.97** | **30.33** | **33.72** | **33.41** | **34.03** | **33.54** | **34.65** | **34.51** |
[Image inpainting task]
Acknowledgements
==========================================================================================
Thiss research was supported in part by NSF grants #1749833, #1749854, and #1661259, and the MassTech Collaborative for funding the UMass GPU cluster.