**On Equivariant and Invariant Learning of Object Landmark Representations**
[Zezhou Cheng](http://people.cs.umass.edu/~zezhoucheng), [Jong-Chyi Su](https://people.cs.umass.edu/~jcsu/), [Subhransu Maji](http://people.cs.umass.edu/~smaji/)
_University of Massachusetts - Amherst_
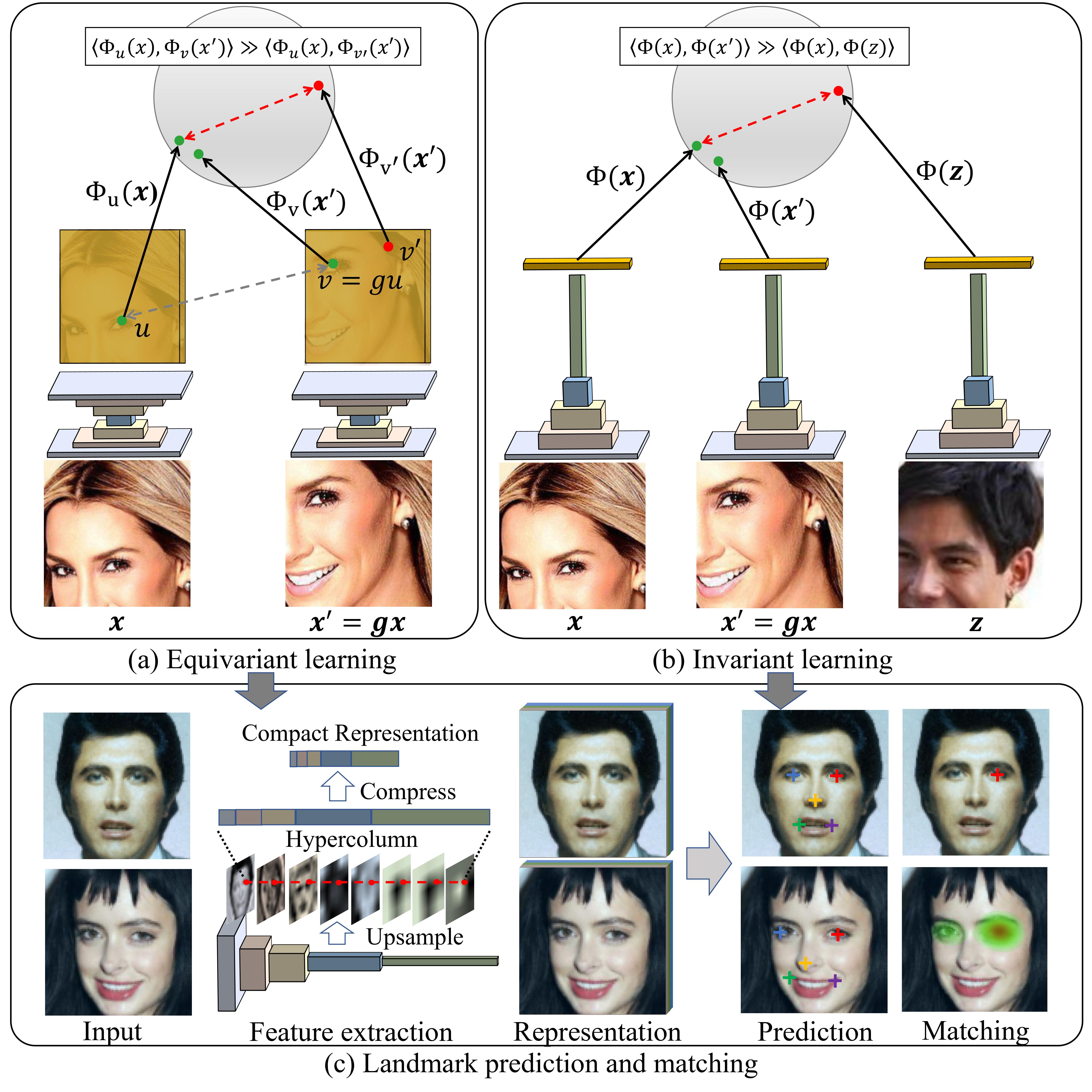 Given a collection of images, humans are able to discover landmarks by modeling the shared geometric structure across instances. This idea of geometric equivariance has been widely used for the unsupervised discovery of object landmark representations. In this paper, we develop a simple and effective approach by combining instance-discriminative and spatially-discriminative contrastive learning. We show that when a deep network is trained to be invariant to geometric and photometric transformations, representations emerge from its intermediate layers that are highly predictive of object landmarks. Stacking these across layers in a ``hypercolumn'' and projecting them using spatially-contrastive learning further improves their performance on matching and few-shot landmark regression tasks. We also present a unified view of existing equivariant and invariant representation learning approaches through the lens of contrastive learning, shedding light on the nature of invariances learned. Experiments on standard benchmarks for landmark learning, as well as a new challenging one we propose, show that the proposed approach surpasses prior state-of-the-art.
Publication
==========================================================================================
**On Equivariant and Invariant Learning of Object Landmark Representations**
Given a collection of images, humans are able to discover landmarks by modeling the shared geometric structure across instances. This idea of geometric equivariance has been widely used for the unsupervised discovery of object landmark representations. In this paper, we develop a simple and effective approach by combining instance-discriminative and spatially-discriminative contrastive learning. We show that when a deep network is trained to be invariant to geometric and photometric transformations, representations emerge from its intermediate layers that are highly predictive of object landmarks. Stacking these across layers in a ``hypercolumn'' and projecting them using spatially-contrastive learning further improves their performance on matching and few-shot landmark regression tasks. We also present a unified view of existing equivariant and invariant representation learning approaches through the lens of contrastive learning, shedding light on the nature of invariances learned. Experiments on standard benchmarks for landmark learning, as well as a new challenging one we propose, show that the proposed approach surpasses prior state-of-the-art.
Publication
==========================================================================================
**On Equivariant and Invariant Learning of Object Landmark Representations**
Zezhou Cheng, Jong-Chyi Su, Subhransu Maji
IEEE International Conference on Computer Vision (ICCV), 2021.
[[PDF](https://openaccess.thecvf.com/content/ICCV2021/papers/Cheng_On_Equivariant_and_Invariant_Learning_of_Object_Landmark_Representations_ICCV_2021_paper.pdf)] [[Supplementary Material](https://openaccess.thecvf.com/content/ICCV2021/supplemental/Cheng_On_Equivariant_and_ICCV_2021_supplemental.pdf)] [[arXiv](https://arxiv.org/abs/2006.14787v2)]
Code
==========================================================================================
[GitHub Link](https://github.com/cvl-umass/ContrastLandmark)
Birds benchmark
==========================================================================================
We collect a challenging dataset of birds where objects appear in clutter, occlusion, and exhibit wider pose variation. It contains 100K images randomly sampled from [iNat 2017 dataset](https://github.com/visipedia/inat_comp/tree/master/2017) under the class "Aves" for unsupervised representation learning and 2006 images from [CUB-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html) for landmark regression.
Here are the lists of images:
[[iNat Aves 100K](datasets/inat_aves_100K.txt)]
[[CUB train/val/test set](datasets/cub_filelist.zip)]
Some examples are as follows:
 Acknowledgements
==========================================================================================
The project is supported in part by Grants #1661259 and #1749833 from the National Science Foundation of United States. Our experiments were performed on the University of Massachusetts, Amherst GPU cluster obtained under the Collaborative Fund managed by the Massachusetts Technology Collaborative. We would also like to thank Erik Learned-Miller, Daniel Sheldon, Rui Wang, Huaizu Jiang, Gopal Sharma and Zitian Chen for discussion and feedback on the draft.
Acknowledgements
==========================================================================================
The project is supported in part by Grants #1661259 and #1749833 from the National Science Foundation of United States. Our experiments were performed on the University of Massachusetts, Amherst GPU cluster obtained under the Collaborative Fund managed by the Massachusetts Technology Collaborative. We would also like to thank Erik Learned-Miller, Daniel Sheldon, Rui Wang, Huaizu Jiang, Gopal Sharma and Zitian Chen for discussion and feedback on the draft.