CMPSCI 691GM : Graphical Models
Spring 2011
Homework #3: Exact Inference for Undirected Graphical Models
Due Dates:
Thursday March 25, 2011: Email working source code
Tuesday March 29, 2011: Email report and revised source code
(26th March) data-tree.dat and truth-tree.dat
have been updated to remove a single word pair that was not a tree.
Please redownload the archive. Alternatively, you may remove the offending word-pair yourself. (16th March)
Note: In this homework we will build upon the
previous homework. The variables and the model, for the most part, will
remain the same, and much of the description is applicable here.
In this homework assignment you will implement and
experiment with exact inference for undirected graphical models and
write a short report
describing your experiences and findings. As in last homework, We will
provide you with
simulated "optical word recognition" data; however, you are
welcome to find and use your own data instead.
Adding Factors Across Words
Due to the computational complexity of exhaustive inference, we
could only work with relatively small models. However, with tools for
faster inference, such as message passing, inference is possible over
much more complex models, which can lead to better accuracy! For
example, consider the skip-chain factors described in the last
homework. These factors lie between characters in a word that have the
similar observed images, and has a high potential when the predicted
characters are the same. However, we can imagine that for images that
are similar across two different words, we would like
the predicted characters to be the same. This homework will be mainly
concerned with these Pair-Skip factors, and the complicated
structures that are defined by them.
Tree Structures
Consider the figure below, consisting of two observed image sequences.
Since none of these sequences have the same image id within themselves,
there are no skip-chain factors. However, there is an image id ("")
that appears in both the sequences. To capture the similarity as
described above, we add the pair-skip factor between these variables.
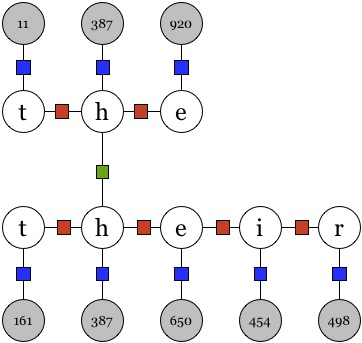
The core task shall consist of models over pairs of such words, i.e.
pairs of words that do not have skip factors within themselves, but
have a single pair-skip factor between them. Note that models over
these pairs will always be a tree, or a simple chain (if the pair-skip
factor is between characters at the beginning/end of the sequences).
The complete model score over pairs of words w1 and w2
will consist of the following three classes of factors:
- OCR Factors,
 :
These factors capture the predictions of a character-based OCR system,
and hence exist between every image variable and its corresponding
character variable. The number of these factors for the pair is len(w1)+len(w2).
The value of factor between an image variable and the character
variable at position i is dependent on img(i) and char(i),
and is stored in ocr.dat file described in the last homework.
:
These factors capture the predictions of a character-based OCR system,
and hence exist between every image variable and its corresponding
character variable. The number of these factors for the pair is len(w1)+len(w2).
The value of factor between an image variable and the character
variable at position i is dependent on img(i) and char(i),
and is stored in ocr.dat file described in the last homework.
- Transition Factors,
 :
Since we also want to represent the co-occurence frequencies of the
characters in our model, we add these factors between all consecutive
character variables for each word. The number of these factors of word w
is (len(w1)-1) + (len(w2)-1). The value of factor between two
character variables at positions i and i+1 is dependent
on char(i) and char(i+1). These values are given to you
in trans.dat file described in the last homework.
:
Since we also want to represent the co-occurence frequencies of the
characters in our model, we add these factors between all consecutive
character variables for each word. The number of these factors of word w
is (len(w1)-1) + (len(w2)-1). The value of factor between two
character variables at positions i and i+1 is dependent
on char(i) and char(i+1). These values are given to you
in trans.dat file described in the last homework.
- Pair-Skip Factors,
 :
These factors exist between pairs of image variables that belong to
different words and have the same id. The value of this factor
depends on the characters, i.e. its value is 5.0 if the
characters are the same, and 1.0 otherwise.
:
These factors exist between pairs of image variables that belong to
different words and have the same id. The value of this factor
depends on the characters, i.e. its value is 5.0 if the
characters are the same, and 1.0 otherwise.
You can download all the data here.
The archive contains the following files:
- ocr.dat, trans.dat: Same as the last homework.
- data-tree.dat (and truth-tree.dat): Dataset to run your
experiments on (see Core Tasks below). The observed dataset (data-tree.dat)
consists observed images of one word on each row (same format as
before), with a empty line between pairs. The true words for this pair
of observed images are stored respectively as rows in truth-tree.dat
(with the empty lines). As before, you should iterate through both the
files together to ensure you have the true words for each pair, along
with their observed images.
- Extra files (...): These files are not necessary for the
core tasks, but may be useful for further fun and your own exploration.
data-*.dat and truth-*.dat contain pairs of words
for loopy graphical models (described in optional tasks), and are in
the same format as data-tree.dat and truth-tree.dat.
Although not needed, you may also use the files from the previous
homework, which are still valid for this homework since the data is
created from the same underlying distribution. The data files are
available here.
If you use of the files from the previous homework, please explain
exactly how you used them.
Core Tasks (for everyone)
- Graphical Model: Implement the graphical model
containing the factors above. For any given assignment to the character
variables, your model should be able to calculate the model score.
Implemention should allow switching between three models:
- OCR model: only contains the OCR factors. Note that this
model treats each word independently.
- Transition model: contains OCR and Transition factors. Note
that this model treats each word independently.
- Pair-Skip model: containing all three types of factors. This
model will be defined over pairs of words.
- Message Passing: Use the message passing inference, as
described in class, to perform infernce on these models. Since these
are tree-structures, the message passing results in exact marginals
over the variables in the tree. Choose a variable as the root node, and
perform a round of forward and backward message passing.
- Model Accuracy: Run your model on the data given in the
file data-tree.dat. Instead of computing the accuracy as in the
last homework, we will use the max-marginal accuracy. First calculate
the marginal probabilities for each chracter variable. For each
variable, pick the alphabet with the highest marginal probability for
that variable, and treat this as the model prediction for the variable.
Using the truth given in truth-tree.dat, compare the accuracy
of the model predictions using the following three metrics:
- Character-wise accuracy: Ratio of correctly predicted
characters (according to max-marginals) to total number of characters
- Word-wise accuracy: Ratio of correctly predicted words
(according to max-marginals) to total number of words
- Average dataset marginals log-likelihood: For each word given
in truth-tree.dat and data-tree, calculate the log of
marginal probability of the word by taking the product of the marginals
of the variables. Compute the average of this value for the whole
dataset.
Compare all of the three models described in (1) using these three
metrics. Also give some examples of words that were incorrect by the
Transition model but consequently fixed by the Pair-Skip model.
Further Fun
Although not required, we hope you will be eager to experiment
further with your model. Here are some ideas for additional
things to try. Of course, you may come up with some even more
exciting ideas to try on your own, and we encourage that. Of
course, be sure to tell us what you did in your write-up.
Message Passing in Loopy Models
The core task only looks at models that are tree-structured, and
message passing results in exact inference without constructing any
clique trees. However often there may be dependencies that do not
result in a tree, for example skip edges between characters within the
same word introduce loops. For the optional tasks, we will
explore exact inference for models that are not trees. To perform exact
inference using message passing in these models, you have to first
convert them into clique trees, and then perform message
passing on the resulting tree. There are potentially four models you
may want to compare: OCR only, add transition factors, add skip
factors, and finally, add pair-skip factors. Use the same potentials
for the skip factors as the last homework, i.e. 5.0 if
the characters match, 1.0 otherwise.
The structures can be divided into the following categories.
- Trees with Skips: Consider models with a single
pair-skip factor, as described above, but with at least one of the the
words consisting of skip edges between themselves, i.e. they look like
the following:
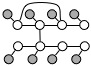
The files (data-treeWS.dat and truth-treeWS.dat) are in
the same format as of the core tasks.
- Loops: Consider models with multiple pair-skip factors,
but without any within-word skip edges, i.e. they look like the
following:
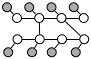
The files (data-loops.dat and truth-loops.dat) are in
the same format as of the core tasks.
- Loops with Skips: Consider models with multiple
pair-skip factors AND with at least one of the words consisting
of skip edges between themselves, i.e. they look like the following:
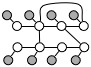
The files (data-loopsWS.dat and truth-loopsWS.dat) are
in the same format as of the core tasks.
Triplets, and more!
In homework 2, we provided the complete observed and labeled data
for exploration, which are also valid for this homework. Consider more
complicated models than ones described above. For example, we can take
triplets of words that have the same observed image for a character,
and a three-way factor that wants the predicted characters to be the
same. Perform exact inference on these complicated models (with
hand-set potentials), and see if you can beat the simpler models in
terms of the max-marginal accuracy.
What to hand in
The homework should be emailed to 691gm-staff@cs.umass.edu.
before 5pm Eastern time on the due date.
- You should provide a short (1-3 page) report describing your
explorations and results. Include a description of the implementation
of your model. Compare the three models on the three metrics, and
discuss the relative improvements by showing examples. Mention the
running time of the model on provided dataset. Also include details of
the optional tasks you did.
- Include the complete source code of your implementation.
Grading
The assignment will be graded on (a) core task completion and
correctness,
(b) effort and creativity in the optional extras (c) quality and
clarity of your written report.
Questions?
Please ask! Send email to 691gm-staff@cs.umass.edu or come to the
office hours. If you'd like your classmates to be able to help answer
your question, feel free to use 691gm-all@cs.umass.edu.