INFO 248: Introduction to Data Science
What is Data Science?
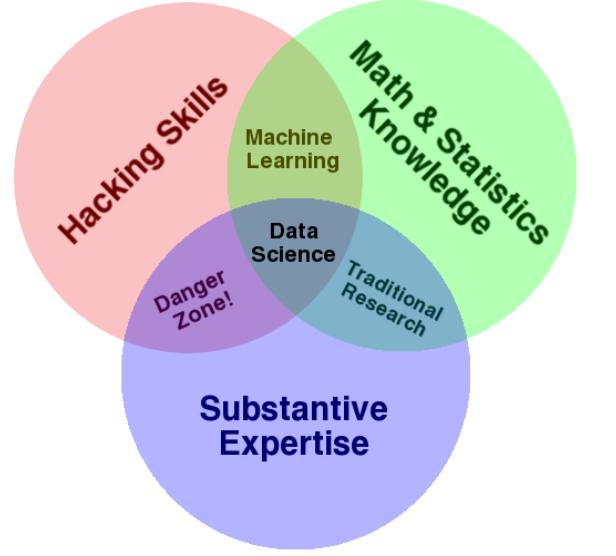 Data Science is the study of how we can transform raw observations (data) into meaningful information. The products of Data Science, such as models, reports, graphs and charts convey information in a concise way so that informed decisions can be made and new hypotheses can be formulated at an increasing rate.
Data Science is the study of how we can transform raw observations (data) into meaningful information. The products of Data Science, such as models, reports, graphs and charts convey information in a concise way so that informed decisions can be made and new hypotheses can be formulated at an increasing rate.
Data Science involves three main areas of focus: computer science, statistics, and knowledge of the domain under study.
About this course: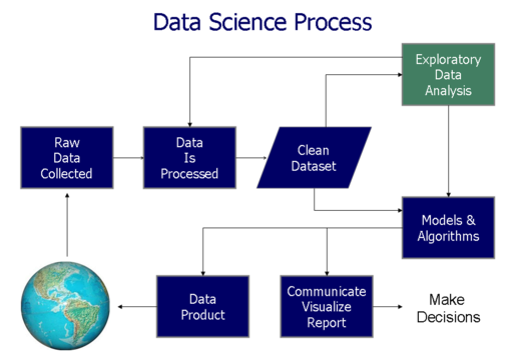 In this course we provide an introduction into the concepts, tools and techniques to perform the following steps in the data science process:
In this course we provide an introduction into the concepts, tools and techniques to perform the following steps in the data science process:
- data acquisition, preparation
- data exploration
- data modeling
- data visualization
All software is open source and freely available. Students will install and use the required software on their machines.
We will use the R software environment including R-studio for data analysis and visualization:
https://www.r-project.org/
https://www.rstudio.com/products/rstudio/download/
We will also use SQLite for the module on querying data from relational databses.
https://sqlite.org
The required text: Doing Data Science by Cathy O'Neil and Rachel Schutt: http://shop.oreilly.com/product/0636920028529.do
Course topics:We will cover basic statistics and progress to clustering, and classification tasks. Machine learning techniques such as K-Means, Partitioning Around Medioids, K-Nearest Neighbor, Naive Bayes, Logistic Regression, Decision Trees, Random Forests, Principle Component Analysis and more will be covered.
We will apply basic machine learning analysis steps: data manipulation, model selection, k-fold cross validation, model evaluation.
The emphasis will be on the suitability and application of these modeling techniques to specific data sets, although the mathematical basis of these algorithms will be explained.
We will study data sets from several domains, including Education, Science, Finance, Health, and Social Media.
Course format:The course meets twice weekly. Each meeting consists of a presentation of new material followed by hands-on work that applies the concepts presented.
Several projects will be assigned.
A midterm and final exam will be administered.
Who should take this course?This course is designed for Informatics Majors. This course is NOT intended for Computer Science majors and does not count as an elective towards the CS major.
Prerequisites: At least an introductory programming course, such as COMPSCI 121, and a statistics course such as STAT 240 (or OIM 240, or PSYCH 240, or STAT 515, or RES ECON 212, or SOCIOL 212).