This problem set has two major parts: (1) calculating alignments as part of IBM Model 1, and (2) constructing a Naive Bayes document classifier. These both use Bayes Rule to calculate posterior probabilities. In both instances you will also conduct analysis of what your code is doing and how good it is at capturing natural language phenomena. We supply some code that visualizes the models' posteriors, but you will construct some new ones too. This is skill is part of model and algorithm diagnosis, an invaluable skill when implementing and inventing NLP and ML algorithms.
Some logistical notes:
We hae broken up the problem set into two different .ipynb files, because it's annoying to scroll through one huge file. This file contains the instructions as well as Part 1. The second file contains Part 2.
Please only edit cells that are marked "ANSWER HERE" (or something similar). Do not add new cells if possible. Due to uninteresting technical details of how .ipynb files work, this allows us to grade faster and more easily.
Again, this makes grading a lot easier.
We are providing not just the notebooks, but multiple other files. There are data files for some of the questions. But there are also code files. To load Python code from an external file, you use the Python module system, which means a command like
import ibm
Then functions inside that files are available as e.g. ibm.argmax([1,2,3,2]).
Please do not modify any external files. You will only turn in the .ipynb files for this assignment. We will run them with the original versions of the files that we gave you.
In part 2, you will implement some functions that rely on other implementations you've done. We recognize that this is tricky in terms of grading if you have a bug in the upstream function. When grading, we will test each function in isolation, using correct implementations of the upstream functions.
In this section, your job is to implement one part of IBM Model 1: calculating the posterior alignments. You will be given (1) an "English" sentence $\vec{e}$, (2) a "Foreign" sentence $\vec{f}$, and (3) the $t(f|e)$ translation probabilities, which give the probability of a single englishword-to-foreignword transformation $p(f_i | \vec{e}, a_i) = p(f_i | e_{a_i})$. Recall that IBM Model 1 assumes there exists a latent alignment variable $a_i$ for every position in the Foreign sentence, which can point to any position in the English sentence; you have to calculate the posterior distribution over the possible positions it could point to. That is, for every position $i$ in the Foreign-sentence, you need to calculate the posterior distribution $P(a_i=j | \vec{f},\vec{e})$, which is a vector of probabilities for each possible $j$ position in the English-sentence. This describes the model's posterior belief about which English token did $f_i$ "come from".
We are using the notation from Collins notes on the IBM Models. (We are not using the notation from lecture, which is reversed. I thought you all would find the Collins notes easier to read and follow.) Note that the first part of the Collins notes focus on Model 2, which has parameters for the alignment prior $p(a_i)$ (which Collins calls $q(.)$); but in Model 1 this prior is uniform across the English tokens. Model 1 is described later in the Collins notes.
Question 1 (15 points)
Implement the function calc_alignment_posterior in the cell below. Please keep your entire answer within this cell.
import ibm # Has utility functions you can use if you like
def calc_alignment_posterior(ftoks, etoks, t_ef):
# This must return a list of lists, such that
# delta[i][j] is P(a_i=j | f,e).
# Rows are foreign tokens. Columns are english tokens.
# INPUTS
# - ftoks: a list of strings, the tokens of the foreign sentence.
# - etoks: a list of strings, the tokens of the english sentence.
# - t_ef: this is a dict-of-dicts where P(f|e) is represented as t_ef[e][f].
# Collins calls these 'm' and 'l'
flen = len(ftoks)
elen = len(etoks)
# We give code for the following strategy: create the return matrix,
# 'delta', filled with dummy values. Then fill them in and return 'delta'.
# Feel free to delete this code and use a different approach if you like.
# Initialize with fake values
delta = [[-999 for j in range(elen)] for i in range(flen) ]
# Calculate the posteriors and store them into the matrix 'delta'.
# ANSWER STARTS HERE
# ANSWER ENDS HERE
return delta
Sanity check: execute the following code, for the Foreign sentence ['a','b','c'] and English sentence ['<null>','C','B'], given the toy translation model.
# DO NOT EDIT THIS CELL
from __future__ import division
# Toy model for testing. "English" is upper-case letters, "Foreign" is lower-case letters.
# This is t(a|A), t(a|B), etc.
# Note that t(a|A)+t(b|A)+t(c|A) = 1, but t(a|A)+t(a|B)+t(a|C)+t(a|<null>) does not.
toymodel = {
'<null>': {'a':1.0/3, 'b':1.0/3, 'c':1.0/3},
'A': {'a':0.98, 'b':0.01, 'c':0.01},
'B': {'a':0.1, 'b':0.8, 'c':0.1},
'C': {'a':0.1, 'b':0.1, 'c':0.8},
}
calc_alignment_posterior(['a','b','c'], ['<null>','C','B'], toymodel)
It should return something like the following (we've truncated some numbers for readability):
[[0.625, 0.1875, 0.1875],
[0.27, 0.08, 0.64],
[0.27, 0.64, 0.08]]
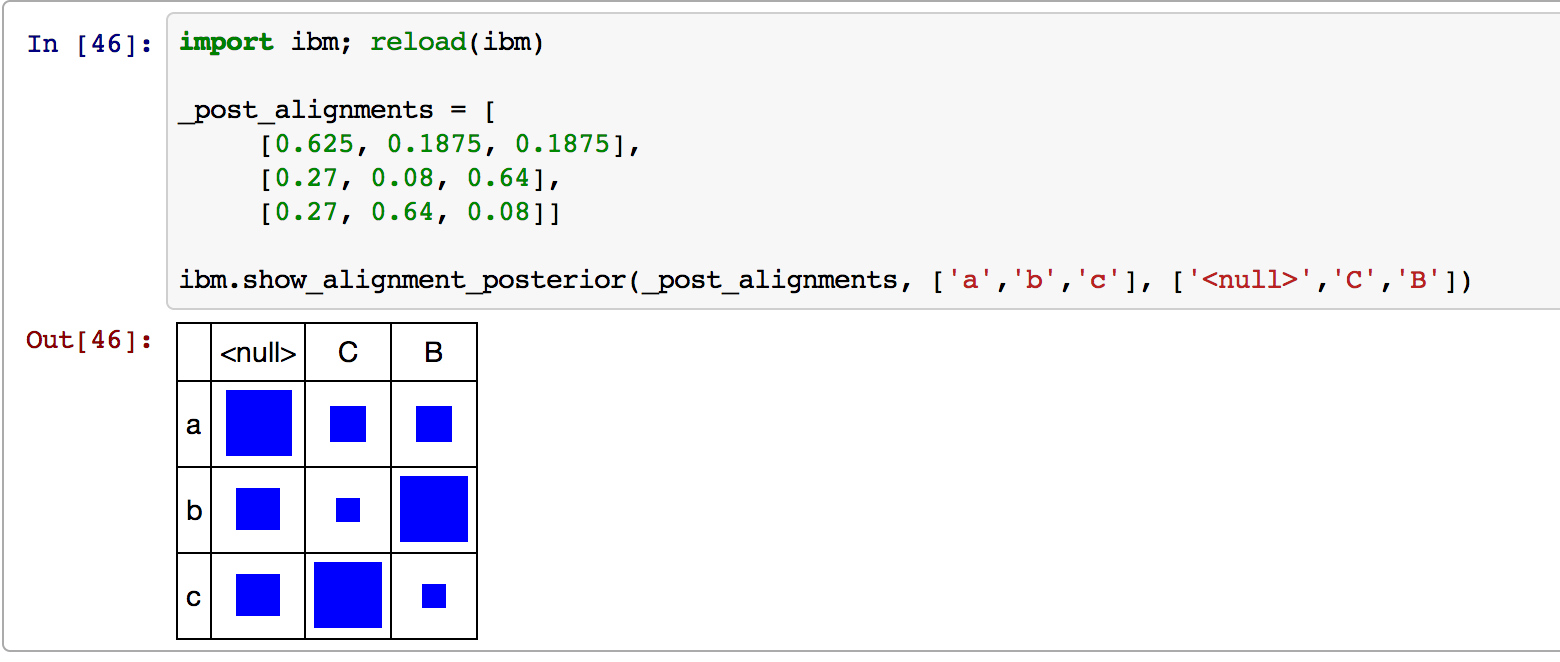
We have provided a function that visualizes a posterior alignment matrix, like the output of calc_alignment_posterior(). We have tested it in Chrome and Safari. The next cell should work standalone, even without implementing the previous section. Please execute the cell to see how it works. It simply shows the table, where in each cell, there's a blue box that's sized proportionally to the probability in that cell. Here is a screenshot of what it should look like.
import ibm
_post_alignments = [
[0.625, 0.1875, 0.1875],
[0.27, 0.08, 0.64],
[0.27, 0.64, 0.08]]
ibm.show_alignment_posterior(_post_alignments, ['a','b','c'], ['<null>','C','B'])
Question 2 (1 point)
Where does the model think the word "c" came from?
Answer: ANSWERME
Question 3 (1 point)
Where does the model think the word "a" came from? Why does it think so, instead of the other options? (It may be helpful to write print/write out the translation table on paper and look at it at the same time.)
Answer: ANSWERME
We have provided for you a $t(f|e)$ translation table that we trained with the EM algorithm. It was trained on 10,000 German-English sentences from the Europarl dataset (from the EU Parliament). The sentences are in the plaintext file de-en.short_10k.lowtok included this directory. You can view it with your favorite text editor. Our preprocessing had two steps: (1) tokenization (using nltk.word_tokenize), and (2) lowercasing all words. EM training proceeded for 30 iterations and took just a few minutes. Normally, machine translation training is done with much larger datasets (and thus higher quality models).
First, load the translation table. It is a dictionary with the same structure as toymodel above, except much bigger. The next cell loads it, and for one word, prints out the most probable translations, and their probabilities.
import json
ttable = json.load(open("ttable.json"))
print "%d words in e vocab" % len(ttable.keys())
print "Most probable translations of ."
tprobs = ttable["."]
pairs = sorted(tprobs.items(), key=lambda (f,p): -p)[:10]
print u" ".join("%s:%.3f" % (f,p) for f,p in pairs)
Question 4 (5 points)
Comment on the quality of this translation table (translations of an English period into German). Which of the translations are good? Which are bad? Why is it making errors that it's making? It may be useful to open the training data text file in a text editor, and search for particular words in order to understand how they're used. You can also look up German words on http://dict.leo.org/ though these ones are pretty simple (Herr="Mr.", Frau="Mrs.").
Answer: ANSWERME
Next, calculate alignments on the following sentence pairs, which are from the real dataset, using this translation model. Answer questions about the model's analysis of them. You should not have to change the code cells.
ee=u"<null> resumption of the session".split()
ff=u"wiederaufnahme der sitzungsperiode".split()
pa = calc_alignment_posterior(ff,ee,ttable)
ibm.show_alignment_posterior(pa, ff,ee)
Here, the German word "der" is being used in the genitive case, which indicates posession, so "X der Y" means "Y's X" or "X of Y" (information here).
Question 5 (4 points)
Comment on the quality of the above alignment. Look up the German words on http://dict.leo.org/ in order to help figure out how good it is.
Answer:
ANSWERME
bitext=u"mehr als 60 % der polen sind für den verfassungsvertrag . ||| over 60 % of poles support the constitutional treaty ."
ff,ee=[x.strip() for x in bitext.split("|||")]
ee,ff=ee.split(),ff.split()
ibm.show_alignment_posterior(calc_alignment_posterior(ff,ee,ttable), ff,ee)
Question 6 (4 points) Comment on the quality of this alignment. What's going on with the English word "Poles"?
Answer:
ANSWERME
bitext=u"so also denken die polen über die europäische union . ||| that is what they think about the european union ."
ff,ee=[x.strip() for x in bitext.split("|||")]
ee,ff=ee.split(),ff.split()
ibm.show_alignment_posterior(calc_alignment_posterior(ff,ee,ttable), ff,ee)
Question 7 (4 points) Comment on the quality of this alignment. Are there aspects of the training data that are important here? (If you look at the data file, note that the sentences are actually randomly ordered.)
Answer:
ANSWERME
Part 2 of this problem set is in another file.
{kind=link}