
Ashish Singh
PhD Student
College of Information and Computer Sciences
University of Massachusetts, Amherst
Email: ashishsingh[at]cs.umass.edu
I am a third-year Ph.D. student working with Prof. Erik Learned-Miller in the Computer Vision Lab. I have broad interests in computer vision, machine learning, and artificial intelligence in general.
Research Projects

Half&Half: New Tasks and Benchmarks for Studying Visual Common Sense
Making intelligent decisions about unseen objects given only partial observations is a fundamental component of visual common sense. In this work, we formalize prediction tasks critical to visual common sense and introduce the Half&Half benchmarks to measure an agent's ability to perform these tasks.
[PDF]Ashish Singh*, Hang Su*, SouYoung Jin, Huaizu Jiang, Chetan Manjesh, Geng Luo, Ziwei He, Li Hong, Erik G. Learned-Miller, and Rosemary Cowell, "Half&Half: New Tasks and Benchmarks for Studying Visual Common Sense", CVPR 2019 Workshop on Vision Meets Cognition .
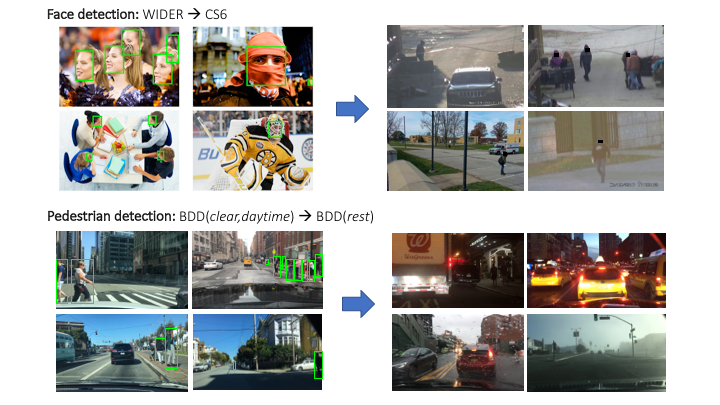
Self-training on Hard Examples for Unsupervised Domain Adaptation
Domain adapation of object detectors using unlabeled video. It provides a straight-forward way to adapt to novel domains with minimal dependence on hyper-parameters or a labeled validation set. This is a follow up of our earlier work at ECCV 2018 that mined unlabeled videos to automatically collect hard examples for object detectors.
[PDF][Project][Code]Aruni RoyChowdhury, Prithvijit Chakrabarty, Ashish Singh, SouYoung Jin, Huaizu Jiang, Liangliang Cao and Erik Learned-Miller. "Automatic adaptation of object detectors to new domains using self-training", Computer Vision and Pattern Recognition (CVPR), 2019. .
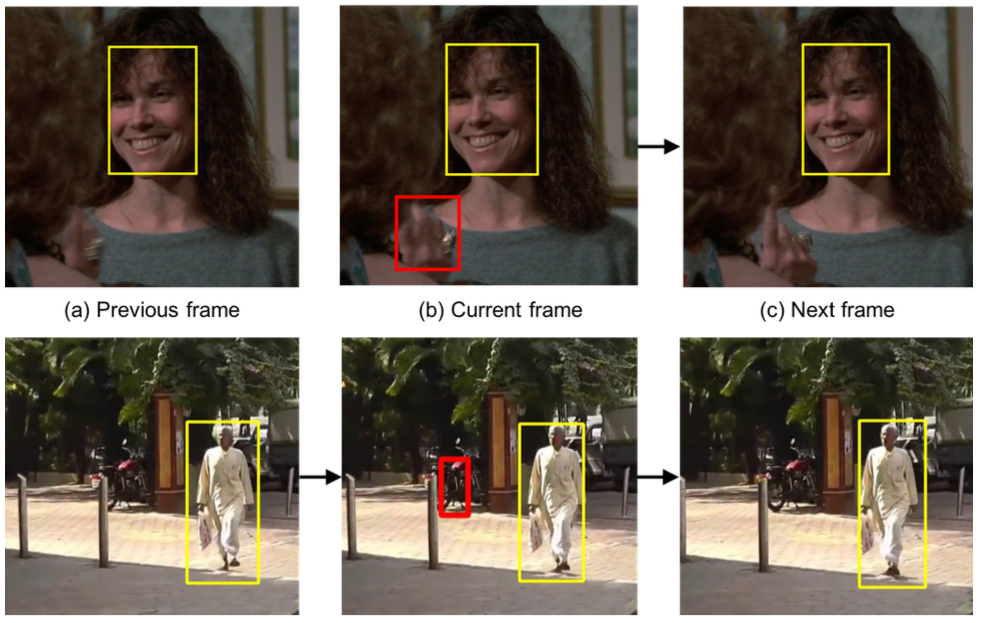
Unsupervised Hard Example Mining from Videos for Improved Object Detection
In this work, we show how large numbers of hard negatives can be obtained automatically by analyzing the output of a trained detector on video sequences. In particular, detections that are isolated in time, i.e., that have no associated preceding or following detections, are likely to be hard negatives. We describe simple procedures for mining large numbers of such hard negatives (and also hard positives) from unlabeled video data.
[PDF][Project][Code]SouYoung Jin*, Aruni RoyChowdhury*, Huaizu Jiang, Ashish Singh, Aditya Prasad, Deep Chakraborty, and Erik Learned-Miller. "Unsupervised hard example mining from videos for improved object detection", European Conference on Computer Vision (ECCV), 2018..