[Intro to NLP, CMPSCI 585, Fall 2014]
This exercise is to annotate 100 tweets for names, in a manner similar to the data we already have. We will use the results of this exercise to help create the final test set for evaluation. This is due by the morning of Thursday, 11/20. It should take about a half hour to complete.
[Warning: a small percentage of these tweets are inappropriate content; we’ve observed several that are pornography, and there’s various racism, sexism, etc. as well. We’re just using what we get from twitter.com, whose content filtering systems are imperfect. If you feel uncomfortable with this task, please let us know and we can arrange an alternative exercise.]
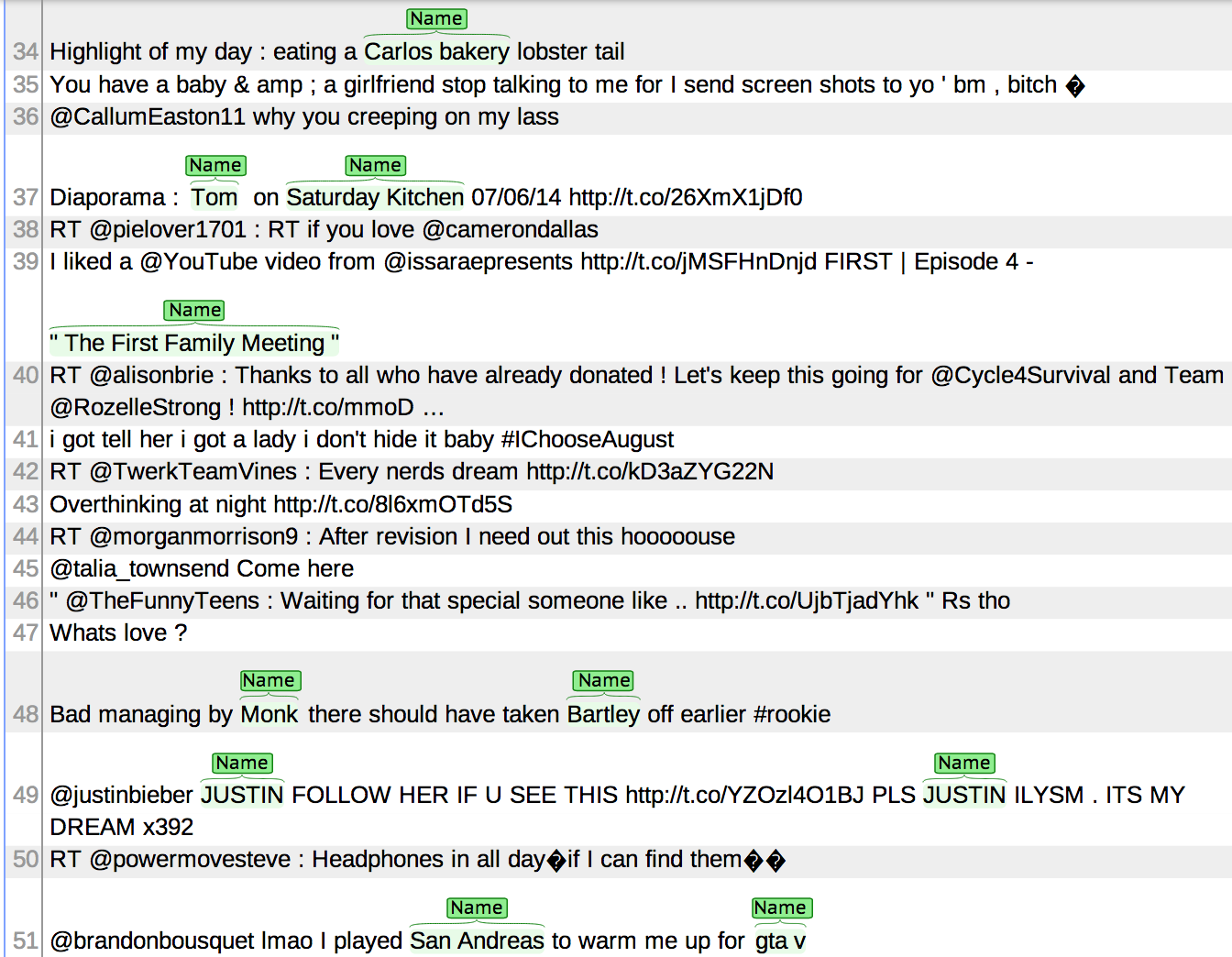
Once you log in to the web interface (username guest, password guest), you can highlight a span of tokens in order to tag it as a name. You can also click on annotations in order to delete or change them. The text has already been tokenized (and the tokenization is imperfect). Once you finish making your annotations, you are done; there is nothing more to submit. Here is an example of what this will look like:
There are many judgment calls to make as to what a name is. For our purposes, please use the following conventions (which are intended to be similar to dataset from Ritter et al. 2011 that we have been using).
The following are NOT considered to be names.
The following criteria may help identify names.
Also,
[Toledo] city hall, but [Boston Celtics].
Toledo city hall refers to the city hall for the city of Toledo. But Boston Celtics does not mean a group of Celtic people from Boston; rather, together it refers to a sports team. (This is called “semantic noncompositionality”. Names tend to be non-compositional.)Please use the URL that should have been emailed to you. These are tweets sampled from public messages on twitter.com. They are tweets that Twitter’s own language ID system has identified as English (we noticed a few false positives in a sample of 200).
Please review your tweets once or twice after you finish your first annotation pass. You’ll probably notice you made errors earlier, or you might change your mind on some of them.
If you want to annotate more, let us know and we can give you more tweets to annotate (as many as you want). This may be a good way to improve your NER system, too, just by having more training data. (You can also fix errors you find in the training data we gave you, as well.)