Reverse Data Management
Reverse-engineering data transformations to understand, diagnose, and manipulate data
Forward and Reverse Data Transformations
Data transformations, functions from an input data source to an output data source, are ubiquitous today and can be found in data integration, data exchange, and ETL tools. The natural evolution of data follows the directionality of the transformations, from source to target. Most database research focuses on forward-moving data flows: source data is subjected to transformations and evolves through queries, aggregations, and view definitions to form a new target data instance, possibly with a different schema. This forward paradigm underpins most data management tasks today, such as querying, data integration, data mining, clustering, and indexing. Database systems are particularly efficient at handling forward transformations, which typically generate new target data, as opposed to modifying the source data.

This project contrasts forward processing with reverse data management: the handling of reverse transformations that perform actions on the input data, on behalf of desired outcomes in the output data. Reverse transformations modify the source data rather than generate a new target data instance. Some examples of reverse transformations include updates through views, data generation, and data cleaning and repair. Reverse transformations are, by necessity, conceptually more difficult to define, and computationally harder to achieve. Today, however, as increasingly more of the available data is derived from other data, there is an increased need to be able to modify the input in order to achieve a desired effect on the output, motivating a systematic study of reverse data management.
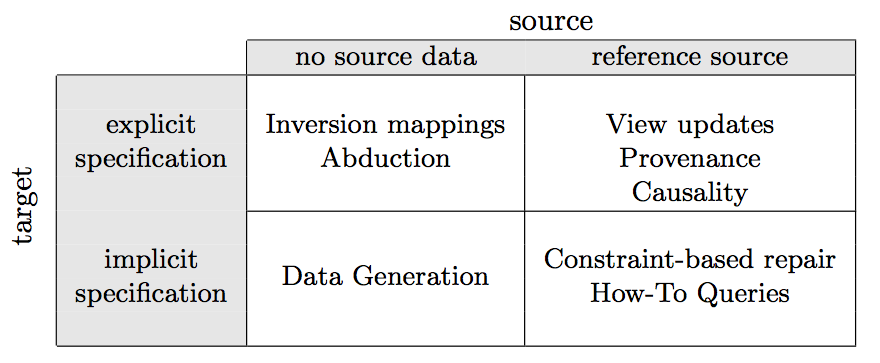
Our goal is to develop Reverse Data Management techniques that facilitate:
- Understanding data and query results.
- Diagnosing errors in data systems.
- Manipulating data based on desirable outcomes.
Publications
Sainyam Galhotra, Yuriy Brun, and Alexandra Meliou.
ESEC/FSE 2017.
[
 Paper]
QFix: Diagnosing errors through query histories
Paper]
QFix: Diagnosing errors through query historiesXiaolan Wang, Alexandra Meliou, and Eugene Wu.
SIGMOD 2017.
[
Paper]
EXStream: Explaining Anomalies in Event Stream MonitoringHaopeng Zhang, Yanlei Diao, and Alexandra Meliou.
EDBT 2017.
[
Paper]
QFix: Demonstrating error diagnosis in query historiesXiaolan Wang, Alexandra Meliou, and Eugene Wu.
SIGMOD 2016.
[
Paper]
Preventing Data Errors with Continuous TestingKıvanç Muşlu, Yuriy Brun, and Alexandra Meliou.
ISSTA 2015.
[
Paper]
Error Diagnosis and Data Profiling with Data X-RayXiaolan Wang, Mary Feng, Yue Wang, Luna Dong, and Alexandra Meliou.
VLDB 2015.
[
Paper]
Data X-Ray: A Diagnostic Tool for Data Errors
Xiaolan Wang, Luna Dong, and Alexandra Meliou.
SIGMOD 2015.
[
Paper]
A Characterization of the Complexity of Resilience and Responsibility for Self-join-free Conjunctive Queries
Cibele Freire, Wolfgang Gatterbauer, Neil Immerman, and Alexandra Meliou
PVLDB 2015.
[
Paper]
[ Extended version]
Reverse Data Management
Alexandra Meliou, Wolfgang Gatterbauer, and Dan Suciu.
VLDB 2011.
[
Paper],
[ Slides]
Slides]